SQL
1 基本概念
DBMS(Datebase Managment System)
DBS(Datebase System)
DBA(Datebase Administrator)
1.1 SQL分类
-
Data Definition Language(DDL)
-
Data Manipulation Language(DML)
-
Data Control Language(DCL)
-
数据库(database)- 保存有组织的数据的容器(通常是一个文件或一组文件)。 -
数据表(table)- 某种特定类型数据的结构化清单。 -
模式(schema)- 关于数据库和表的布局及特性的信息。模式定义了数据在表中如何存储,包含存储什么样的数据,数据如何分解,各部分信息如何命名等信息。数据库和表都有模式。 -
列(column)- 表中的一个字段。所有表都是由一个或多个列组成的。 -
行(row)- 表中的一个记录。 -
主键(primary key)- 一列(或一组列),其值能够唯一标识表中每一行。
关系型数据库关系型数据库(RDB,Relational Database)就是一种建立在关系模型的基础上的数据库。关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多)。
2 创建表
create table <table_name>( |
primary key vs unique
-
主键只能有一个
-
主键属性不能为NULL
-
UNQIUE可以为NULL
-
NOT NULL- 指示某列不能存储 NULL 值。 -
UNIQUE- 保证某列的每行必须有唯一的值。 -
PRIMARY KEY- NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。 -
FOREIGN KEY- 保证一个表中的数据匹配另一个表中的值的参照完整性。 -
CHECK- 保证列中的值符合指定的条件。 -
DEFAULT- 规定没有给列赋值时的默认值。
3 Select查询
DISTINCT 用于返回唯一不同的值。它作用于所有列,也就是说所有列的值都相同才算相同。
LIMIT 限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。
#属性重命名 |
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE/not like | 搜索某种模式,%(any string) _(any character) |
| IN | 指定针对某个列的多个可能值 |
| AND/OR.NOT |
3.1 查询结果重排序
-
ascending (ASC):升序
-
descending(DESC)
select * from sells where bar='' order by price ASC; |
3.2 子查询
子查询就是指将一个
select查询(子查询)的结果作为另一个 SQL 语句(主查询)的数据来源或者判断条件。子查询可以被用作a value or set
子查询可以用在from和where子句中
子查询可以嵌入 SELECT、INSERT、UPDATE 和 DELETE 语句中,也可以和 =、<、>、IN、BETWEEN、EXISTS 等运算符一起使用。
子查询常用在 WHERE 子句和 FROM 子句后边:
-
当用于
WHERE子句时,根据不同的运算符,子查询可以返回单行单列、多行单列、单行多列数据。子查询就是要返回能够作为WHERE子句查询条件的值。 -
当用于
FROM子句时,一般返回多行多列数据,相当于返回一张临时表,这样才符合FROM后面是表的规则。这种做法能够实现多表联合查询。
3.2.1 IN
<tuple> IN (<subquery>) |
3.2.2 EXISTS
EXISTS(<subquery>) is true if and only if the subquery result is not empty. |
3.2.3 ANY
x = ANY(<subquery>) is a boolean condition that is true iff x equals at least one |
3.2.4 ALL
x <> ALL(<subquery>) is true iff for every tuple t in the relation, x is not equal to |
3.2.5 Bag语义
-
Sslect-from-where:bag semantics
-
union 、intersection、difference:set semantic
3.2.6 控制Duplicate Elimination
Force the result to be a set by SELECT DISTINCT . . . |
4 连接(join)
SQL JOIN 子句用于将两个或者多个表联合起来进行查询。连接表时需要在每个表中选择一个字段,并对这些字段的值进行比较,值相同的两条记录将合并为一条。连接表的本质就是将不同表的记录合并起来,形成一张新表。当然,这张新表只是临时的,它仅存在于本次查询期间。
Drinkers(name, addr) |
inner join:2表值都存在
outer join:附表中值可能存在null的情况。
①A inner join B:取交集
②A left join B:取A全部,B没有对应的值,则为null
③A right join B:取B全部,A没有对应的值,则为null
④A full outer join B:取并集,彼此没有对应的值为null
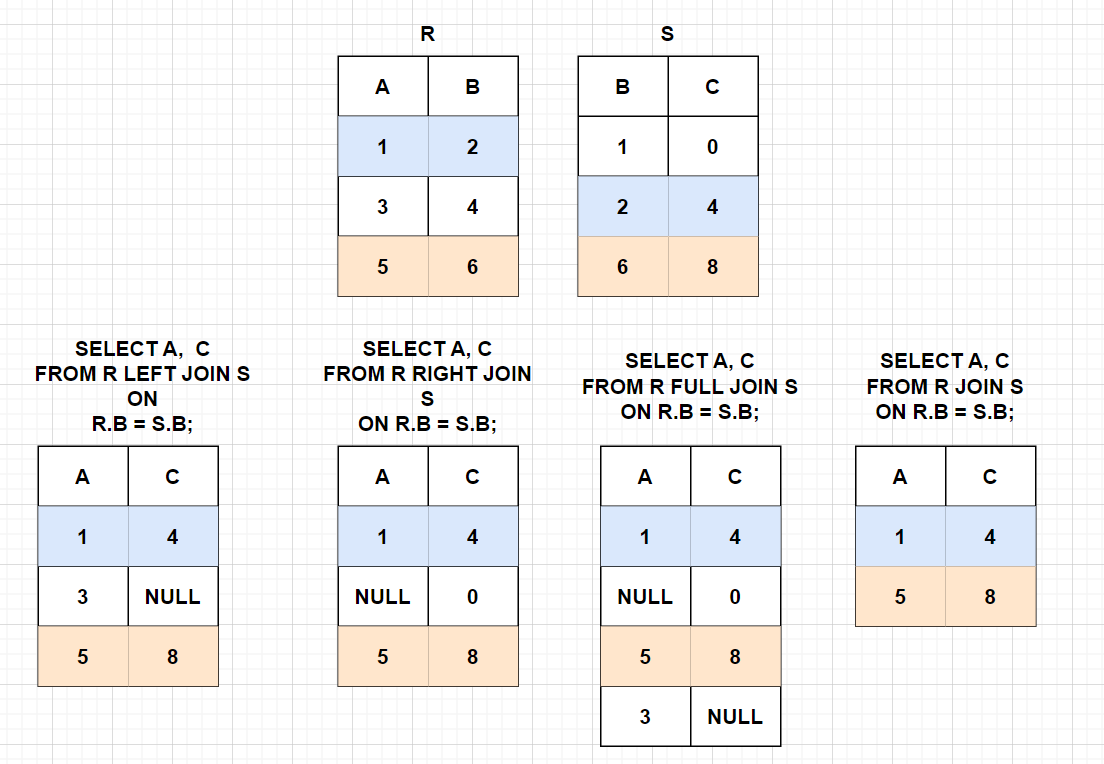
| 连接类型 | 说明 |
|---|---|
| INNER JOIN 内连接 | (默认连接方式)只有当两个表都存在满足条件的记录时才会返回行。 |
| LEFT JOIN / LEFT OUTER JOIN 左(外)连接 | 返回左表中的所有行,即使右表中没有满足条件的行也是如此。 |
| RIGHT JOIN / RIGHT OUTER JOIN 右(外)连接 | 返回右表中的所有行,即使左表中没有满足条件的行也是如此。 |
| FULL JOIN / FULL OUTER JOIN 全(外)连接 | 只要其中有一个表存在满足条件的记录,就返回行。 |
| SELF JOIN | 将一个表连接到自身,就像该表是两个表一样。为了区分两个表,在 SQL 语句中需要至少重命名一个表。 |
| CROSS JOIN | 交叉连接,从两个或者多个连接表中返回记录集的笛卡尔积。 |
where>group by>having>order by
添加更新
if not exists (select 1 from t where id = 1)
insert into t(id, update_time) values(1, getdate())
else
update t set update_time = getdate() where id = 1
5 外键约束
外键约束的作用是维护表与表之间的关系,确保数据的完整性和一致性。
主键:是唯一标识一条记录,不能有重复的,不允许为空,用来保证数据完整性
外键:是另一表的主键, 外键可以有重复的, 可以是空值,用来和其他表建立联系用的。所以说,如果谈到了外键,一定是至少涉及到两张表。例如下面这两张表:
6 聚合函数
sum、avg、count、min、max:can be applied to a column in
a SELECT clause to produce that aggregation on the column
使用 DISTINCT 可以让汇总函数值汇总不同的值。
7 分组(group by)
SELECT-FROM-WHERE-GROUP BY
查询出的关系
If any aggregation is used, then each element of the SELECT list
must be either:
-
Aggregated, or
-
An attribute on the GROUP BY list.
8 HAVING
SELECT-FROM-WHERE-GROUP BY-HAVING
-
having用于对汇总的group by结果进行过滤。 -
having一般都是和group by连用。 -
where和having可以在相同的查询中。
9 组合
9.1 union、intersection、except
满足任一条件满足所有条件满足指定条件(排除满足条件的部分)
From Likes(drinker, beer) and Sells(bar, beer, price), Find the beer which is the favorite of ‘Lynn Conway’ or the price is above 40
(SELECT beer FROM Likes |
10 数据库修改
INSERT INTO <relation>(属性列表) VALUES ( <list of values>); |
11 第一范式、第二范式、第三范式、BCNF
-
第一范式:列不可再分,要求数据库表的每一列都是不可分割的原子数据项。
-
第二范式:建立在第一范式基础上,消除部分依赖。确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
-
第三范式:建立在第二范式基础上,消除传递依赖。第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。