term(任期)
Leader发出heartbeat(AppendEntries RPC不带有log entries)
Raft is a consensus algorithm that is designed to be easy to understand. It’s equivalent to Paxos in fault-tolerance and performance.

1 2A Leader election(领导人选举)
-
网络延迟、分区、包丢失、复制和重新排序。
This election term will continue until a follower stops receiving heartbeats and becomes a candidate.
导致Follower进行选举的原因
-
网络延迟或者包丢失没有在选举超时前收到心跳
-
网络分区而导致收不到心跳(disconnect)
-
Leader宕机、崩溃(crash)
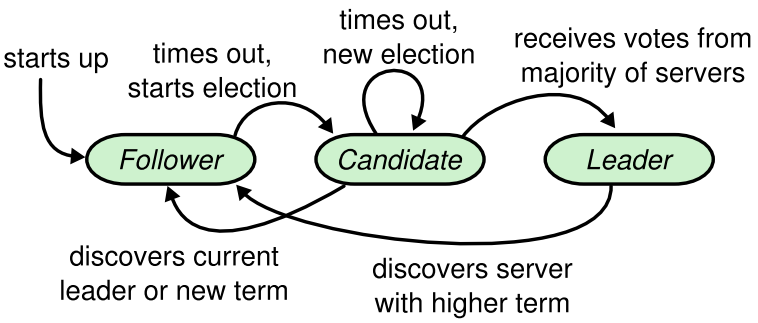
1.1 节点类型
-
Leader:负责发起心跳,响应客户端,创建日志,同步日志。 -
Candidate:Leader 选举过程中的临时角色,由 Follower 转化而来,发起投票参与竞选。 -
Follower:接受 Leader 的心跳和日志同步数据,投票给 Candidate。态转换
-
Follower$\rightarrow$Candidate(超时:一段时间内未收到heartbeat)
Leader(AppendEntries RPC)
-
term过时:
- 发送心跳发现Server的term号大于自身的term号(已经选出新的Leader,将自己状态变为Follower)
- 收到RequestVote发现更高term号
Candidate(RequestVote RPC)
-
term过时
- 收到新的Leader的心跳,请求投票时发现大于自身的term号
- 收到RequestVote RPC的response,返回的term号更大
Follower:被动的,对来自Leader和Candidate的请求进行相应
-
收到Leader的心跳,且term号大于自身term号(更新自身term号)
-
收到Candidate请求
Server:
-
拒绝过时term的请求
1.2 选举超时时间和心跳时间
-
心跳间隔时间(heartbeat timeout):Leader 会向所有的 Follower 周期性发送心跳来保证自己的 Leader 地位。
-
选举超时时间(election timeout):如果一个 Follower 在一个周期内没有收到心跳信息或者请求投票信息,就叫做选举超时,并开始一次新的选举。
这两个时间需要保持一定的关系,网络无故障时,在选举超时前应该收到心跳,以保持Leader不变。选举超时时间至少需要大于AppendEntries RPC发送到server所需的最长时间。
1.2.1 选举超时时间更新
-
candidate成为leader
-
candidate收到RequestVote response并变为follower
-
server收到AppendEntries
-
server收到RequestVote
-
leader收到AppendEntries response发现更高term号
1.2.2 超时选举实现
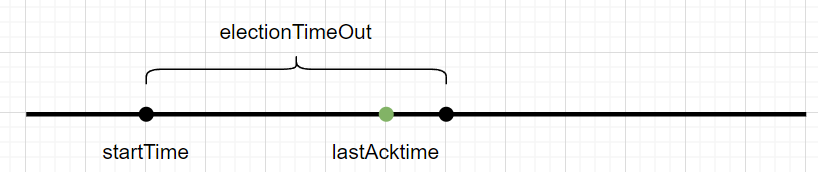
在raft结构体中定义laskAcktime,在收到leader的heartbeat或者candidate的投票请求时,要更新选举超时时间这里没有通过定时器在到达选举超时时间后触发选举操作,而是首先记录下当前时间,然后让ticker协程sleep一段时间。当再次唤醒后,如果laskAcktime在startTime之后,说明在选举超时前收到了相关信号。
1.3 注意点
1.3.1 sendAppendEntries没有启用新的协程
在sendHeartbeat中,异步发送sendAppendEntries,向所有server发送heartbeat,无需等待RPC完成。因为leader可能无法与其他server通信,或者server不可达,由于等待rpc返回,造成超时重新选举
异步发送RequestVote,并且收到超过半数选票后就成为Leader,发送心跳
go test -race -run 2A
2 2B Log replication(日志复制)
Leader Completeness: if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms. §5.4
State Machine Safety: if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index. §5.4.3
-
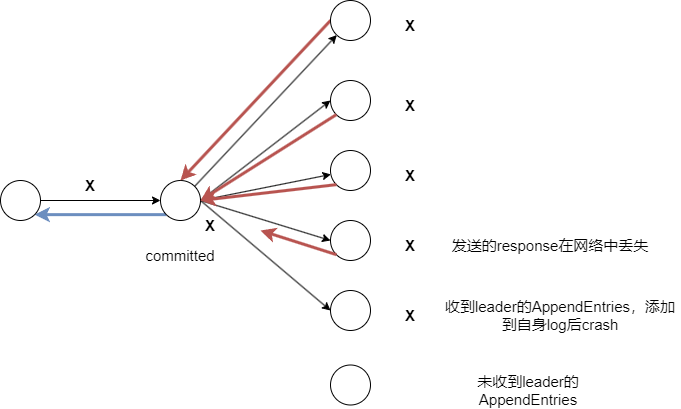
leader收到client请求,将entry添加到log
-
leader将添加的entry复制到其他server
-
如果大多数server成功复制entry,则该entry已经committed
-
已经committed的entry需要应用到机器上,lastApplied代表已经执行的命令
2.1 Election restriction(5.4.1)

log backtracking
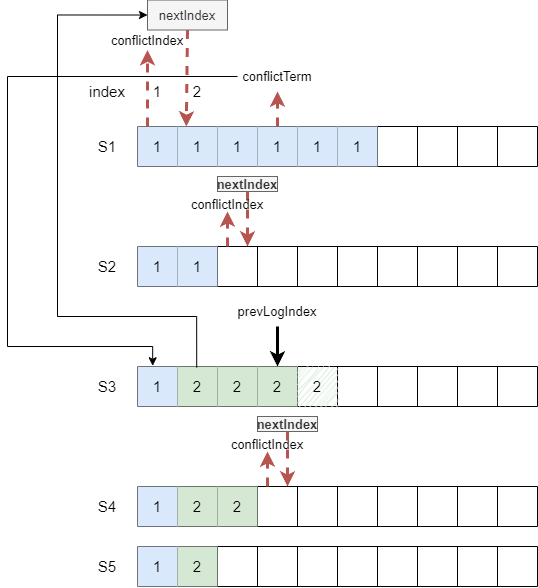
S1首先成为leader,成功发送了第一个entry
S1和S2与其他服务器断开后重连
2.2 注意点
遇到的bug
s1断联,添加了一系列entry
重连后,新的leader通过heartbeat更新了s1的commitindex,而此时s1的log还未更新
3 2C
persist |
3.1 Bug
同一任期选出两个leader
乱序收到RPC response
AppendEntries的RPC response与当前term不一致
在变成follower时都重置了election time
4 2D
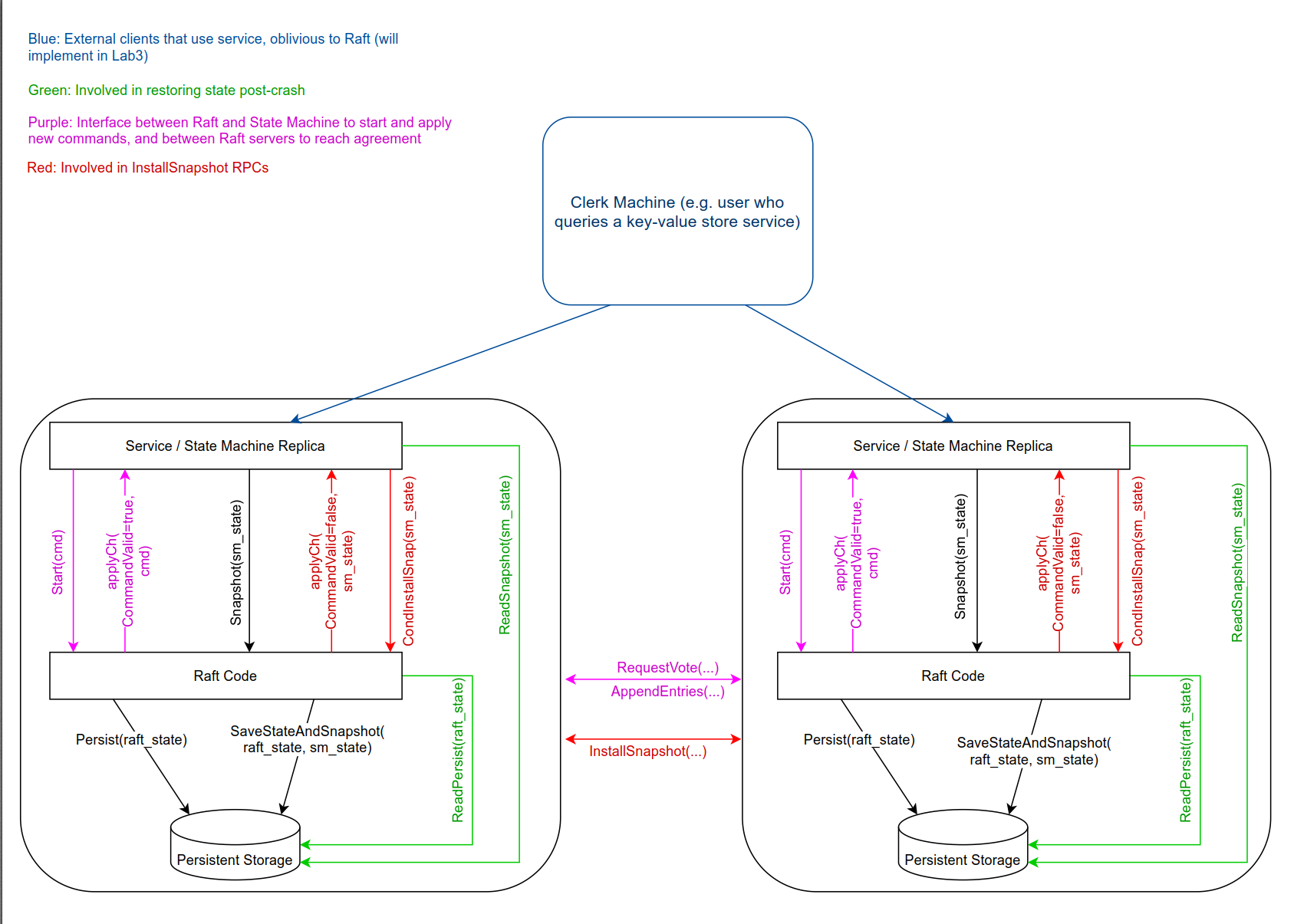
4.1 bug
-
每10条command创建一个快照,快照会调用rf.mu这个互斥锁,当存在新的提交命令时,通过applyCh管道进行发送,而测试程序调用snapshot需要获取互斥锁,无法读取管道中的数据,则会产生死锁
-
apply error: server 2 apply out of order, expected index 10, got 18当snapshot存在未commit的命令时,snapshot和log分别放入applyCh,应当一次性放入applyCh
| result | the time that the test took in seconds | the number of Raft peers | the number of RPCs sent during the test | the total number of bytes in the RPC messages | the number of log entries that Raft reports were committed |
|---|---|---|---|---|---|
| PASSED | 3.9 | 3 | 490 | 154736 | 207 |
5 问题
5.1 raft
raft是分布式一致性算法,基于复制状态机的思想,对于初始状态一样的节点,在他们上运行同样的命令,还会保持一致性的状态。raft主要包括领导者选举、日志复制、持久化以及快照等。
5.2 raft应用场景
Raft 是一种共识算法,通常用于构建分布式系统中的可靠复制日志。它可以应用于各种分布式系统的场景,包括但不限于:
-
分布式数据库系统:Raft 可以用于构建分布式数据库系统,确保数据的一致性和可靠性,比如 etcd、Consul 等。
-
分布式文件系统:在分布式文件系统中,Raft 可以确保各个节点之间的文件操作的一致性,比如 HDFS、Ceph 等。
-
分布式消息队列:Raft 可以确保消息队列中的消息传递和处理的一致性,比如 Kafka 等。
-
分布式计算:在分布式计算中,Raft 可以确保各个节点之间的任务调度和执行的一致性,比如 Spark、MapReduce 等。
-
分布式存储系统:Raft 可以确保分布式存储系统中数据的可靠性和一致性,比如分布式缓存系统如 Redis、分布式块存储系统如 Ceph 等。
总的来说,任何需要在分布式环境中保证一致性和可靠性的系统都可以考虑使用 Raft 算法来实现。
6 参考
Raft (thesecretlivesofdata.com)(Raft图示)
Raft Q&A[6]
paxos 2015版的lab
hashicorp/raft: Golang implementation of the Raft consensus protocol (github.com)