JVM (3):JDK监控和故障处理工具
-
jps(JVM Process Status): 类似 UNIX 的ps命令。用于查看所有 Java 进程的启动类、传入参数和 Java 虚拟机参数等信息; -
jstat(JVM Statistics Monitoring Tool): 用于收集 HotSpot 虚拟机各方面的运行数据;gc情况、垃圾回收统计
-
jinfo(Configuration Info for Java) : Configuration Info for Java,显示虚拟机配置信息; -
jmap (Memory Map for Java) : 生成堆转储快照;内存布局、堆信息
-
jhat(JVM Heap Dump Browser) : 用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果; -
jstack (Stack Trace for Java) : 生成虚拟机当前时刻的线程快照,线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。
1 JVM参数
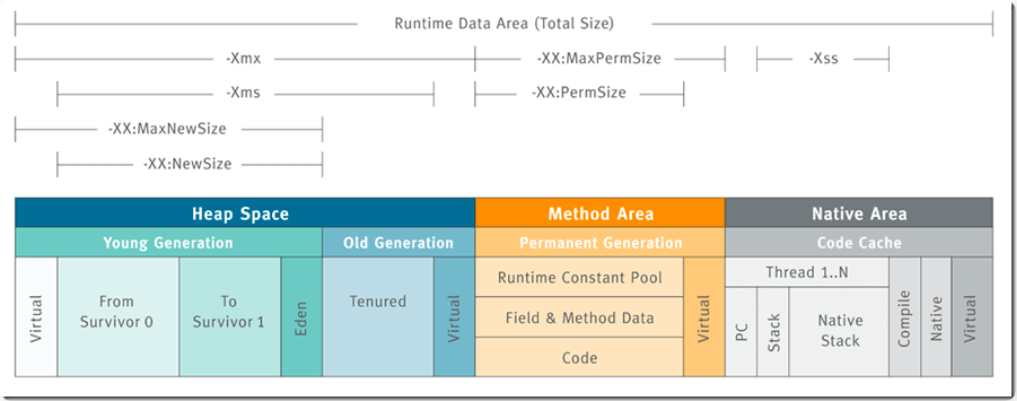

1.1 堆参数
初始堆(memory start)大小、最大堆大小 |
2 jstack :生成虚拟机当前时刻的线程快照
jstack(Stack Trace for Java)命令用于生成虚拟机当前时刻的线程快照。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合.
生成线程快照的目的主要是定位线程长时间出现停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等都是导致线程长时间停顿的原因。线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做些什么事情,或者在等待些什么资源。
3 OOM类型
-
虚拟机栈:
-
固定大小:申请不到栈帧报 StackOverflow
-
无限大小:申请不到栈帧报 OutOfMemory
-
堆:忘记是不是能固定大小了
-
jvm内存满了,对象分配不到堆了就会报OutOfMemory
-
方法区:(面试官提示,感谢)
-
方法区里面的常量池也是会不断加入数据的
-
一直调用string.intern()方法会不断加字符串到字符串常量池导致OOM
4 OOM排查
OOM 全称 “Out Of Memory”,表示内存耗尽。当 JVM 因为没有足够的内存来为对象分配空间,并且垃圾回收器也已经没有空间可回收时,就会抛出这个错误。产生原因:
- 分配过少:JVM 初始化内存小,业务使用了大量内存;或者不同 JVM 区域分配内存不合理
- 代码漏洞:某一个对象被频繁申请,不用了之后却没有被释放,导致内存耗尽
内存泄漏:申请使用完的内存没有释放,导致虚拟机不能再次使用该内存,此时这段内存就泄露了。因为申请者不用了,而又不能被虚拟机分配给别人用
内存溢出:申请的内存超出了 JVM 能提供的内存大小,此时称之为溢出
4.1 OOM类型
java.lang.OutOfMemoryError: PermGen space
Java7 永久代(方法区)溢出,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。每当一个类初次加载的时候,元数据都会存放到永久代
一般出现于大量 Class 对象或者 JSP 页面,或者采用 CgLib 动态代理技术导致
我们可以通过 -XX:PermSize 和 -XX:MaxPermSize 修改方法区大小
Java8 将永久代变更为元空间,报错:java.lang.OutOfMemoryError: Metadata space,元空间内存不足默认进行动态扩展
java.lang.StackOverflowError
虚拟机栈溢出,一般是由于程序中存在 死循环或者深度递归调用 造成的。如果栈大小设置过小也会出现溢出,可以通过 -Xss 设置栈的大小
虚拟机抛出栈溢出错误,可以在日志中定位到错误的类、方法
java.lang.OutOfMemoryError: Java heap space
Java 堆内存溢出,溢出的原因一般由于 JVM 堆内存设置不合理或者内存泄漏导致
如果是内存泄漏,可以通过工具查看泄漏对象到 GC Roots 的引用链。掌握了泄漏对象的类型信息以及 GC Roots 引用链信息,就可以精准地定位出泄漏代码的位置
如果不存在内存泄漏,就是内存中的对象确实都还必须存活着,那就应该检查虚拟机的堆参数(-Xmx 与 -Xms),查看是否可以将虚拟机的内存调大些
tasklist | findstr "java" |
4.2 案例1(Xmn=Xmx,老年代内存为0)
Heap Space Size = Young Space Size + Old Space Size,而-Xmn参数控制的正是 Young 区的大小,当堆区被 Young Gen 完全挤占,又有对象想要升代到 Old Gen 时,发现 Old 区空间不足,于是触发 Full GC,触发 Full GC 以后呢,通常又会面临两种情况:
-
Young 区又刚好腾出来一点空间,对象又不用放到 Old 区里面了,皆大欢喜
-
Young 区空间还是不够,对象还是得放到 Old 区,Old 区空间不够,卒,喜提
OOM -
诶,就是奔着 Old 区去的,管你 Young 不 Young,Old 区空间不够,卒,喜提
OOM
这个就解释了为什么系统刚刚启动时,会有一个短时间正常工作的现象,随后,当某段程序触发 Old Gen 升代时,就会发生随机的OOM错误。那么什么时候对象会进入老年代呢?这里也很有意思,不妨结合日志里面出现OOM的地方,对号入座:
-
经历足够多次数 GC 依然存活的对象
-
申请一个大对象(比如超过 Eden 区一半大小)
-
GC 后 Eden 区对象大小超过 S 区之和
-
Eden 区 + S0 区 GC 后,S1 区放不下
换言之,正常情况下,-Xmn参数总是应当小于-Xmx参数,否则就会触发OOM错误。
5 CPU占用过高,排查和处理
在Linux环境下,项目出现CPU占用过高的情况时,可以按照以下步骤进行排查和处理:
-
定位高CPU占用的进程:
- 使用
top命令查看系统中CPU占用率最高的进程。
- 使用
-
分析进程中的线程:
- 如果发现某个进程的CPU占用率特别高,可以使用
top -H -p [PID]来查看该进程中各个线程的CPU占用情况。 - 找出占用CPU最高的线程ID。
- 如果发现某个进程的CPU占用率特别高,可以使用
-
转换线程ID为16进制:
- 使用
printf "%x\n" [线程ID]命令将线程ID转换为16进制格式。
- 使用
-
获取线程堆栈信息:
- 使用
jstack [进程PID] | grep [线程ID的16进制] -A 30命令获取该线程的Java堆栈信息(如果是Java进程)。这可以帮助定位到具体的代码行或方法调用。 - 如果不是Java进程,可以使用
gdb或其他相应的调试工具来获取线程的堆栈信息。
- 使用
-
分析代码和日志:
- 根据堆栈信息,检查相关的代码逻辑,看是否有死循环、资源泄露、复杂计算等导致CPU占用过高的问题。
- 同步问题导致的死锁、过度的上下文切换,或者资源竞争等问题。这可能会涉及到分析操作系统级别的线程调度,JVM内部锁的状态,以及可能的I/O等待、网络延迟等问题。
- 同时检查应用程序的日志,看是否有异常或错误信息与高CPU占用相关。
-
性能剖析
- 使用性能剖析工具(如VisualVM, YourKit, JProfiler等)进行实时监控,找出CPU占用率高的方法。
- 这些工具可以提供热点(hot spots)功能,显示哪些方法占用最多的CPU时间。
-
处理措施:
- 如果是代码问题,修复相应的bug或优化算法。
- 如果是配置问题,调整系统或应用程序的配置参数。
- 如果是资源不足,考虑增加硬件资源或优化资源分配。
- 如果是外部攻击,加强系统的安全防护措施。线上Java 高CPU占用、高内存占用排查思路_java程序,在线metaspace使用高-CSDN博客助你了解jvm命令,查找JVM堆栈信息,分析性能问题 - 知乎 (zhihu.com)
CPU飙高的排查方案及思路_cpu冲高排查思路-CSDN博客
6 参考
JVM参数最重要的JVM参数总结 | JavaGuide
美团面试:熟悉哪些JVM调优参数,幸好我准备过!-CSDN博客
JDK监控和故障处理工具总结 | JavaGuide
生产事故-记一次特殊的OOM排查 - 程语有云 - 博客园 (cnblogs.com)
YGC问题排查,又让我涨姿势了! | HeapDump性能社区