1 ZAB
1.1 Raft算法和ZAB算法的异同点
| Leader选举 | 选举已提交(commit)最大编号日志所在节点 | 选举最大ZXID的Proposal(含未提交)所在节点 |
|---|---|---|
| 新Leader是否提交前任Leader未提交的消息 | 提交 | 提交 |
| Leader数量 | 1 | 1 |
| Quorum作用范围 | Leader任内有效,以自身消息为准 | Leader任内有效,以自身消息为准 |
2 Zookeeper理论知识
2.1 数据模型
使用了 znode 作为数据节点 。znode 是 zookeeper 中的最小数据单元,每个 znode 上都可以保存数据,同时还可以挂载子节点,形成一个树形化命名空间。
每个 znode 都有自己所属的 节点类型 和 节点状态。
其中节点类型可以分为 持久节点、持久顺序节点、临时节点 和 临时顺序节点。
-
持久节点:一旦创建就一直存在,直到将其删除。
-
持久顺序节点:一个父节点可以为其子节点 维护一个创建的先后顺序 ,这个顺序体现在 节点名称 上,是节点名称后自动添加一个由 10 位数字组成的数字串,从 0 开始计数。
-
临时节点:临时节点的生命周期是与 客户端会话 绑定的,会话消失则节点消失 。临时节点 只能做叶子节点 ,不能创建子节点。
-
临时顺序节点:父节点可以创建一个维持了顺序的临时节点(和前面的持久顺序性节点一样)。
2.2 会话
2.3 ACL
2.4 Watcher机制
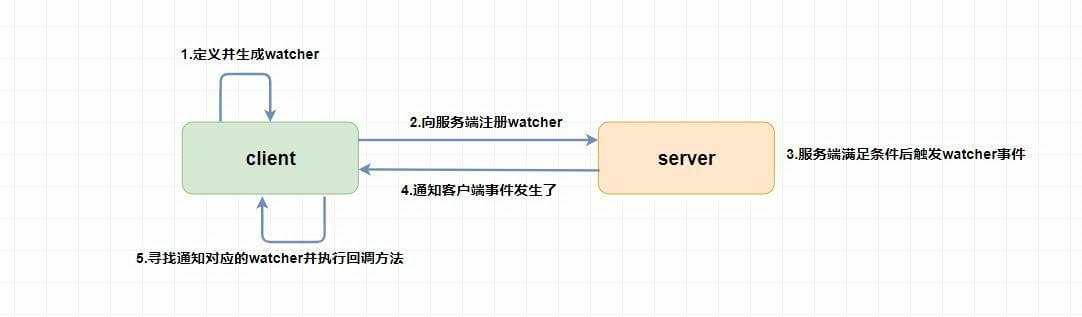
Watcher 为事件监听器,是 zk 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端 注册 指定的 watcher ,当服务端符合了 watcher 的某些事件或要求则会 向客户端发送事件通知 ,客户端收到通知后找到自己定义的 Watcher 然后 执行相应的回调方法 。
3 Zookeeper应用场景
3.1 选主
3.2 数据发布/订阅
3.3 分布式锁
创建节点的唯一性,我们可以让多个客户端同时创建一个临时节点,创建成功的就说明获取到了锁 。然后没有获取到锁的客户端也像上面选主的非主节点创建一个 watcher 进行节点状态的监听,如果这个互斥锁被释放了(可能获取锁的客户端宕机了,或者那个客户端主动释放了锁)可以调用回调函数重新获得锁。
共享锁和独占锁
有序的节点
规定所有创建节点必须有序,当你是读请求(要获取共享锁)的话,如果 没有比自己更小的节点,或比自己小的节点都是读请求 ,则可以获取到读锁,然后就可以开始读了。若比自己小的节点中有写请求 ,则当前客户端无法获取到读锁,只能等待前面的写请求完成。
如果你是写请求(获取独占锁),若 没有比自己更小的节点 ,则表示当前客户端可以直接获取到写锁,对数据进行修改。若发现 有比自己更小的节点,无论是读操作还是写操作,当前客户端都无法获取到写锁 ,等待所有前面的操作完成。
这就很好地同时实现了共享锁和独占锁,当然还有优化的地方,比如当一个锁得到释放它会通知所有等待的客户端从而造成 羊群效应 。此时你可以通过让等待的节点只监听他们前面的节点。
读请求监听比自己小的最后一个写请求节点,写请求只监听比自己小的最后一个节点