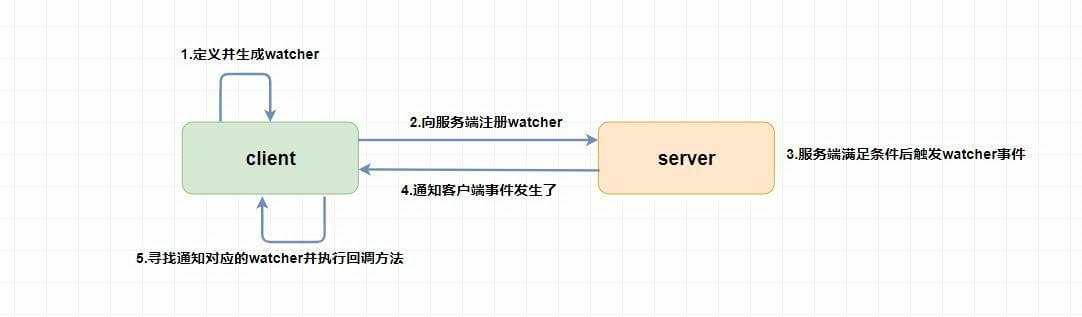
未命名
1 消息队列比较
| 特性 | RabbitMQ | RocketMQ |
kafka |
|---|---|---|---|
| TOPIC(主题模型实现) | 队列模型 | 没有队列的概念,一个主题有多个分区(Partition) | |
| 消费模式 | 集群消费、广播消费 | 集群消费,一个消息只能由一个消费者实例消费 | |
| 支持消息 | 延时消息、事务消息 | 事务消息,不支持延时消息 | |
| 依赖与管理 | Name Server 进行服务发现和路由管理 | 依赖 Zookeeper 进行分区的元数据管理、Leader 选举和消费组协调 | |
| 使用场景 | RocketMQ 的 Queue 更加灵活,支持更复杂的消息路由和消费策略,适合需要精细化控制和顺序性保证的场景,如金融交易、电商订单处理等。 | Kafka 的 Partition 注重高吞吐量和简单性,适合需要处理大量数据流的场景,如实时日志收集、大数据处理等。 | |
| 消息吞吐量 | 万级 | 10万级 | 10万级,吞吐量高。一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| 时效性 | us级,这是rabbitmq的一大特点,延迟是最低的 | ms级 | ms级 |
| 可用性 | 高(主从架构) | 非常高(分布式架构) | 非常高(分布式架构),kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 优劣势总结 | erlang语言开发,性能极其好,延时很低;吞吐量到万级,MQ功能比较完备而且开源提供的管理界面非常棒 | 提供较少的核心功能,但是提供超高的吞吐量,ms级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展同时kafka最好是支撑较少的topic数量即可,保证其超高吞吐量而且kafka唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集 |
|
-
消费推拉模式
客户端消费者获取消息的方式,Kafka和RocketMQ是通过长轮询Pull的方式拉取消息,RabbitMQ、Pulsar、NSQ都是通过Push的方式。pull类型的消息队列更适合高吞吐量的场景,允许消费者自己进行流量控制,根据消费者实际的消费能力去获取消息。而push类型的消息队列,实时性更好,但需要有一套良好的流控策略(backpressure)当消费者消费能力不足时,减少push的消费数量,避免压垮消费端。
-
延迟队列
延迟消息的使用场景比如异常检测重试,订单超时取消等,例如:- 服务请求异常,需要将异常请求放到单独的队列,隔5分钟后进行重试;
- 用户购买商品,但一直处于未支付状态,需要定期提醒用户支付,超时则关闭订单;
- 面试或者会议预约,在面试或者会议开始前半小时,发送通知再次提醒。
Kafka不支持延迟消息,RocketMQ开源版本延迟消息临时存储在一个内部主题中,不支持任意时间精度,支持特定的level,例如定时5s,10s,1m等。
-
死信队列
Kafka、RocketMQ、Pulsar、NSQ不支持优先级队列,可以通过不同的队列来实现消息优先级。
RabbitMQ支持优先级消息。 -
优先级队列
2 消息队列选择建议
1.Kafka
Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输,适合产生大量数据的互联网服务的数据收集业务。
大型公司建议可以选用,如果有日志采集功能,肯定是首选kafka了。
2.RocketMQ
天生为金融互联网领域而生,对于高可靠性的场景,尤其是电商里面的订单扣款,以及业务削峰,在大量交易涌入时,后端可能无法及时处理的情况。
RoketMQ在稳定性上可能更值得信赖,这些业务场景在阿里双11已经经历了多次考验,如果你的业务有上述并发场景,建议可以选择RocketMQ。
3.RabbitMQ
RabbitMQ :结合erlang语言本身的并发优势,性能较好,社区活跃度也比较高,但是不利于做二次开发和维护。不过,RabbitMQ的社区十分活跃,可以解决开发过程中遇到的bug。
如果你的数据量没有那么大,小公司优先选择功能比较完备的RabbitMQ。
3 Kafka和RocketMQ
Apache Kafka和Apache RocketMQ都是广泛使用的分布式消息中间件,它们在大数据处理、高并发和高性能场景中发挥着关键作用。尽管它们有相似的应用场景,但两者之间存在一些设计哲学和功能上的差异。下面概述了Kafka和RocketMQ的主要区别与联系:
联系
-
分布式架构:Kafka和RocketMQ都采用了分布式架构,支持高可用性和水平扩展,能够应对大规模数据传输和处理需求。
-
发布/订阅模式:两者都支持发布/订阅(Pub/Sub)模式,允许生产者发布消息到特定主题,而多个消费者可以订阅这些主题来接收消息。
3. 高吞吐量与低延迟:它们都被设计用于高吞吐量和低延迟的消息传递,特别适合实时数据处理和流处理场景。
4. 持久化与可靠性:Kafka和RocketMQ都能保证消息的持久化存储,确保即使在系统故障时也不会丢失数据。
区别 -
设计初衷与背景: Kafka主要用于日志处理和实时数据管道。它更侧重于流处理和数据分析领 。RocketMQ设计时更多考虑了电商等互联网业务场景的需求,如订单处理、分布式事务支持等。
2. 消息模型: Kafka采用分区(Partition)的概念,每个主题可以分为多个分区,分区内部有序,分区间可以并行处理,适合大量数据的并行处理。 RocketMQ除了基本的消息队列模型,还引入了顺序消息和事务消息的支持,更适合需要严格消息顺序或事务一致性的场景。
3. 消息存储: Kafka将消息持久化到磁盘,并使用文件系统特性优化读写性能,通过日志压缩机制管理存储空间。 RocketMQ虽然也支持消息持久化,但它采用一种环形缓冲区的设计来提高内存使用效率,同时支持异步刷盘減少磁盘1/0影响。
Kafka 和 RocketMQ 都是分布式消息队列系统,主要用于处理大规模的数据流和事件流。两者在架构、功能特性、使用场景和性能方面有一些差异。下面是两者的主要区别:
3.1.1 架构与设计
-
Kafka:
- Kafka 设计简单,核心架构围绕主题(Topic)和分区(Partition)展开。Producer 将消息写入分区,Consumer 从分区读取消息。
- Kafka 的 Broker 是无状态的,消费者的位移存储在 Kafka 自身(基于内部主题或外部系统,如 Zookeeper)。
- 强依赖 Zookeeper,用于集群管理、Leader 选举和消费者协调。
-
RocketMQ:
- RocketMQ 是阿里巴巴开源的消息中间件,架构较为复杂,采用多层次设计,包括 Name Server、Broker、Producer、Consumer 等多个组件。
- RocketMQ 的 Broker 具有更多的功能,比如支持消息过滤、延时消息等。
- Name Server 负责服务发现和路由管理,而 Kafka 由 Zookeeper 处理类似功能。
3.1.2 消息模型
-
Kafka:支持发布-订阅模型和点对点模型(通过消费组实现)。消息按分区顺序处理,且默认不支持延迟消息和消息过滤。
-
RocketMQ:支持发布-订阅模型,支持标签(Tag)和关键字(Key)来实现消息过滤。此外,支持定时/延迟消息。
3.1.3 消息可靠性
-
Kafka:通过副本机制(Replication)实现高可用性和数据持久化。副本数量和一致性可以配置。Kafka 允许“至少一次”或“最多一次”的消息投递语义。
-
RocketMQ:也支持多副本,但与 Kafka 不同,RocketMQ 可以配置同步或异步刷盘,并且可以配置主从同步机制来提高可靠性。
3.1.4 性能
-
Kafka:专注于吞吐量,适合处理海量数据。通过顺序写入、零拷贝等优化手段实现了高吞吐量和低延迟。
-
RocketMQ:在性能和功能之间进行了平衡,虽然单节点的吞吐量可能不如 Kafka,但它在功能性(例如消息过滤、延时消息)和灵活性方面更强。
3.1.5 使用场景
-
Kafka:适用于大数据实时处理、日志收集、流式处理等场景,特别是在数据管道和事件流处理方面有较好的表现。
-
RocketMQ:适用于电商、金融等需要高可靠性、低延迟和复杂业务逻辑的场景。阿里巴巴内部广泛使用,尤其在交易系统中。
3.1.6 轻量性
-
Kafka:从功能和架构上看,Kafka 更加简单和轻量。核心组件只有 Broker 和 Zookeeper,易于部署和运维。
-
RocketMQ:架构相对复杂,功能更为丰富,依赖更多的组件,如 Name Server 和多个 Broker。相较于 Kafka,RocketMQ 的功能性增强带来了更高的复杂度。
3.1.7 总结
如果从架构和使用的简洁性来看,Kafka 更加轻量,特别是在分布式消息队列系统的核心场景下。但如果需要更丰富的功能,如消息过滤、延时消息和复杂的消息路由,RocketMQ 可能是更好的选择。
4 分区和队列
Kafka 的 Partition(分区)和 RocketMQ 的 Queue(队列)是两者在消息存储和并行处理方面的关键概念。它们虽然功能类似,但在实现和设计上有一些差异。
4.1.1 概念对比
-
Kafka Partition:
- Kafka 中的 Partition 是一个物理日志文件,Topic 下可以有多个 Partition,每个 Partition 代表一个消息队列。
- 每个 Partition 是独立的消息序列,具有顺序性,但不同 Partition 之间的消息是无序的。
- 分区的数量决定了并行消费的能力,分区越多,可以并行处理的消费者越多。
- Kafka 的分区设计使得消息在写入时可以按分区键(Key)进行分区,使得相同 Key 的消息进入同一分区,保证局部有序。
-
RocketMQ Queue:
- RocketMQ 的 Queue 是 Topic 下的一个逻辑队列,一个 Topic 可以包含多个 Queue,每个 Queue 是一个 FIFO(先进先出)队列。
- 消息按顺序写入 Queue,消费者从 Queue 中顺序读取消息。
- Queue 也是并行消费的基本单元,每个 Queue 可以被不同的消费者并行消费。
- RocketMQ 的 Queue 与 Kafka 的 Partition 类似,都是将消息划分为多个并行处理的单元。
4.1.2 消息路由与分配
-
Kafka:
- 消息的路由由 Producer 根据分区键(Key)决定。如果设置了 Key,相同 Key 的消息会被路由到同一个 Partition,从而保证有序性。如果没有指定 Key,Kafka 默认采用轮询方式分配消息到各个分区。
- 消费者在消费时,根据消费组的配置,可以分配多个分区,每个分区内的消息是顺序消费的。
-
RocketMQ:
- RocketMQ 的消息路由也是由 Producer 决定,Producer 可以指定消息发送到某个特定的 Queue(通过 MessageQueueSelector),或者使用默认的轮询机制。
- 消费者可以消费多个 Queue 的消息,每个 Queue 内的消息是按顺序消费的。
4.1.3 消费模型
-
Kafka:
- Kafka 采用消费组(Consumer Group)的概念,组内的消费者实例共同消费一个 Topic 的所有分区,每个分区只能被一个消费者实例消费。不同的消费组之间相互独立。
- 分区的数量决定了最大并行消费的消费者数量。
-
RocketMQ:
- RocketMQ 也采用消费组的概念,并支持两种消费模式:集群消费(Clustering)和广播消费(Broadcasting)。
- 在集群消费模式下,每个 Queue 只能被组内一个消费者实例消费,多个消费者实例可以并行处理不同的 Queue。
- 在广播模式下,每个消费者实例都会消费所有 Queue 的消息,即消息会被所有消费者实例都消费一次。
4.1.4 消息顺序性
-
Kafka:
- Kafka 在分区内部保证消息的顺序性。如果需要严格的全局有序,可以将所有消息发送到同一个分区,但这会限制并行处理能力。
- 对于局部有序的场景,可以通过分区键来保证同一类消息(相同 Key)按顺序进入同一分区。
-
RocketMQ:
- RocketMQ 通过 Queue 实现消息顺序性,每个 Queue 内部保证消息顺序。
- 可以通过自定义的 MessageQueueSelector 来实现顺序消息的路由,确保相同类型的消息进入同一个 Queue。
4.1.5 扩展性
-
Kafka:
- Kafka 的 Partition 是扩展性的基础,分区数量可以在 Topic 创建后增加,但无法减少。增加分区后,可能会打破现有的消息顺序。
- Kafka 在分区的伸缩性方面表现较好,分区数量增加时可以提高并行处理能力。
-
RocketMQ:
- RocketMQ 的 Queue 数量也是固定的,但在需要时也可以增加 Queue。与 Kafka 相比,Queue 的扩展相对更灵活,但同样会有顺序性破坏的风险。
4.1.6 总结
Kafka 的 Partition 和 RocketMQ 的 Queue 都是为了解决消息系统的并行处理和水平扩展问题。Kafka 的 Partition 更加简单直接,而 RocketMQ 的 Queue 提供了更灵活的路由和消费控制机制。根据具体业务需求,选择适合的模型非常重要。