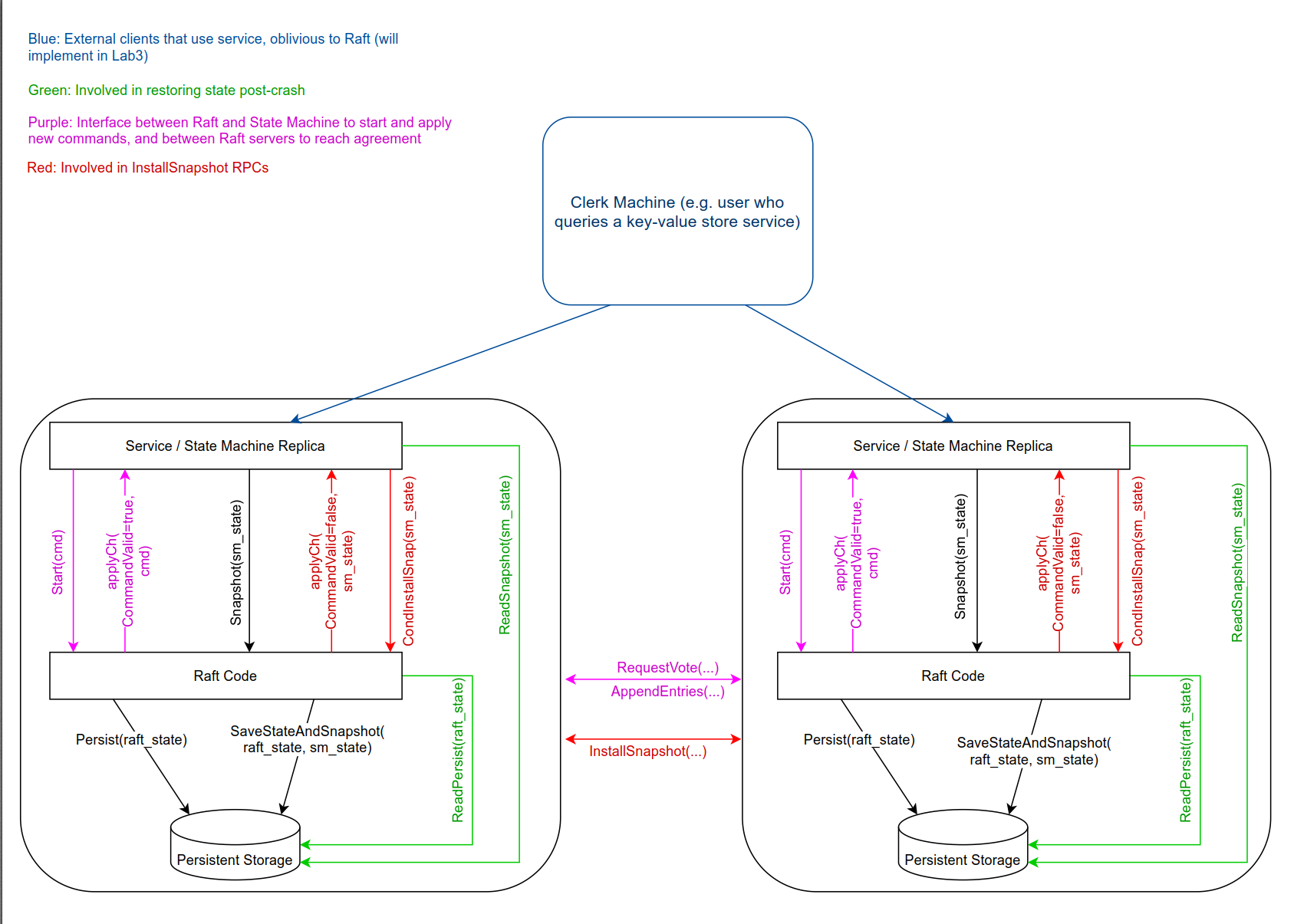
CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。
1 CAP理论
CAP 也就是 Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性)
- 一致性(Consistency) : 所有节点访问同一份最新的数据副本
- 可用性(Availability): 非故障的节点在合理的时间内返回合理的响应(不是错误或者超时的响应)。
- 分区容错性(Partition Tolerance) : 分布式系统出现网络分区的时候,仍然能够对外提供服务。
Quorum机制(法定人数机制
分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。 比如 ZooKeeper、HBase 就是 CP 架构,Cassandra、Eureka 就是 AP 架构,Nacos 不仅支持 CP 架构也支持 AP 架构。
2 数据一致性
一些分布式系统通过复制数据来提高系统的可靠性和容错性,并且将数据的不同的副本存放在不同的机器,由于维护数据副本的一致性代价高,因此许多系统采用弱一致性来提高性能,一些不同的一致性模型也相继被提出。
-
强一致性: 要求无论更新操作实在哪一个副本执行,之后所有的读操作都要能获得最新的数据。
-
弱一致性:用户读到某一操作对系统特定数据的更新需要一段时间,我们称这段时间为“不一致性窗口”。
-
最终一致性:是弱一致性的一种特例,保证用户**最终(即窗口尽量长)**能够读取到某操作对系统特定数据的更新。
[!question] 分布式一致性(缓存与数据库一致性)
- 分布式事务:两段提交
- 分布式锁
- 消息队列、消息持久化、重试、幂等操作
- Raft / Paxos 等一致性算法
3 BASE理论
BASE 是 Basically Available(基本可用)、Soft-state(软状态) 和 Eventually Consistent(最终一致性) 三个短语的缩写。
3.1 基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但是,这绝不等价于系统不可用。
什么叫允许损失部分可用性呢?
软状态指允许系统中的数据存在中间状态(CAP 理论中的数据不一致),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
分布式一致性的 3 种级别:
- 强一致性:系统写入了什么,读出来的就是什么。
- 弱一致性:不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
- 最终一致性:弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。
4 共识算法
共识算法的作用是让分布式系统中的多个节点之间对某个提案(Proposal)达成一致的看法。提案的含义在分布式系统中十分宽泛,像哪一个节点是 Leader 节点、多个事件发生的顺序等等都可以是一个提案。
共识是可容错系统中的一个基本问题:即使面对故障,服务器也可以在共享状态上达成一致。
共识算法允许一组节点像一个整体一样一起工作,即使其中的一些节点出现故障也能够继续工作下去,其正确性主要是源于复制状态机的性质:一组Server的状态机计算相同状态的副本,即使有一部分的Server宕机了它们仍然能够继续运行。
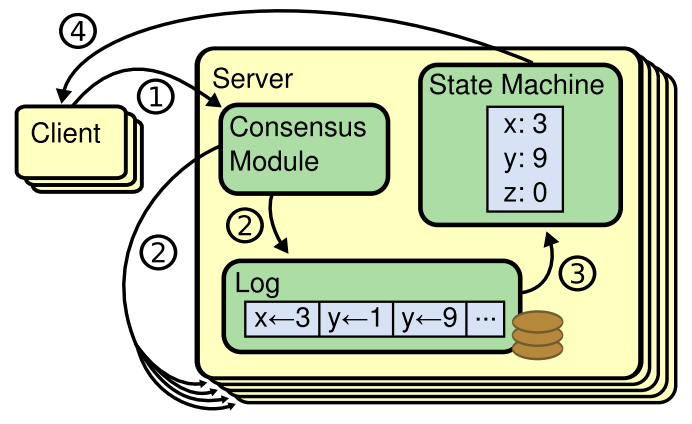
https://javaguide.cn/distributed-system/protocol/raft-algorithm.html
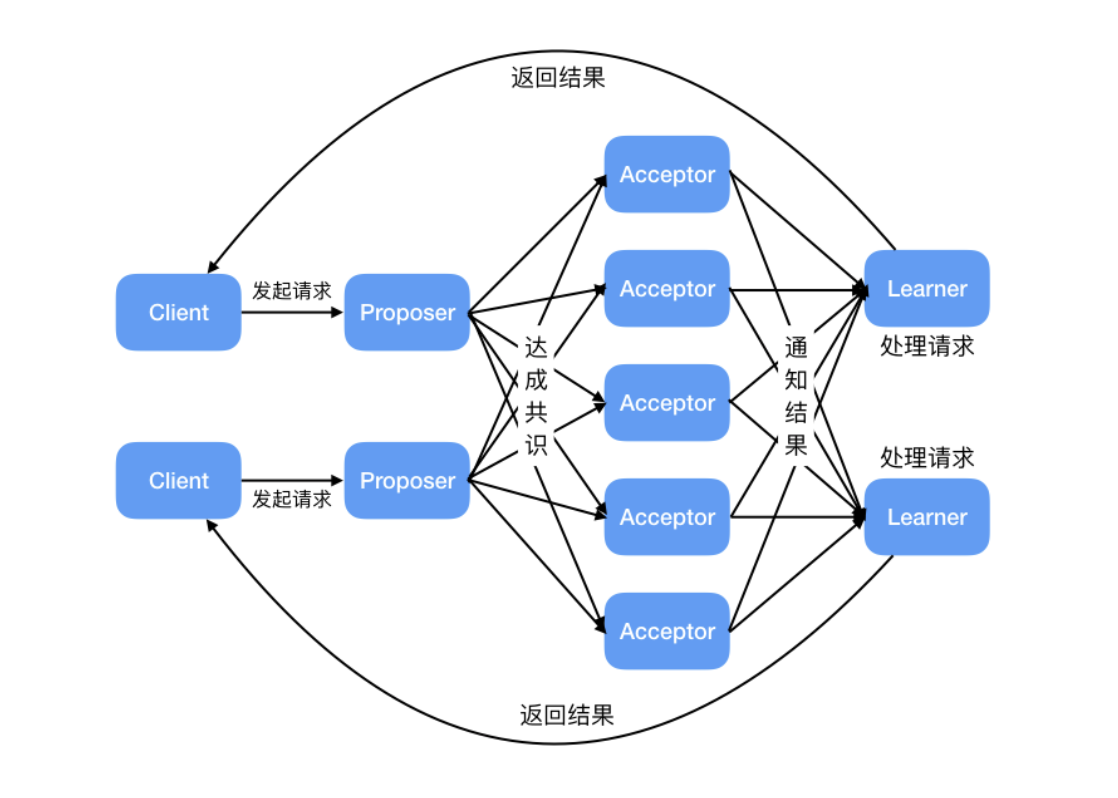
5 Basic Paxos 算法
-
提议者(Proposer):也可以叫做协调者(coordinator),提议者负责接受客户端的请求并发起提案。提案信息通常包括提案编号 (Proposal ID) 和提议的值 (Value)。
-
接受者(Acceptor):也可以叫做投票员(voter),负责对提议者的提案进行投票,同时需要记住自己的投票历史;
-
学习者(Learner):如果有超过半数接受者就某个提议达成了共识,那么学习者就需要接受这个提议,并就该提议作出运算,然后将运算结果返回给客户端。
6 Raft
6.1 基础
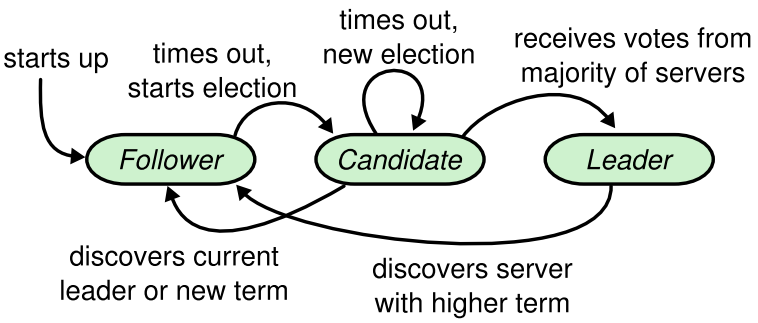
6.1.1 节点类型
-
Leader:负责发起心跳,响应客户端,创建日志,同步日志。
-
Candidate:Leader 选举过程中的临时角色,由 Follower 转化而来,发起投票参与竞选。
-
Follower:接受 Leader 的心跳和日志同步数据,投票给 Candidate。
6.1.2 任期
6.1.3 日志
6.2 领导人选举
raft 使用心跳机制来触发 Leader 的选举。
如果一台服务器能够收到来自 Leader 或者 Candidate 的有效信息,那么它会一直保持为 Follower 状态,并且刷新自己的 electionElapsed,重新计时。
Leader 会向所有的 Follower 周期性发送心跳来保证自己的 Leader 地位。如果一个 Follower 在一个周期内没有收到心跳信息,就叫做选举超时,然后它就会认为此时没有可用的 Leader,并且开始进行一次选举以选出一个新的 Leader。
6.3 日志复制
一旦选出了 Leader,它就开始接受客户端的请求。每一个客户端的请求都包含一条需要被复制状态机(Replicated State Machine)执行的命令。
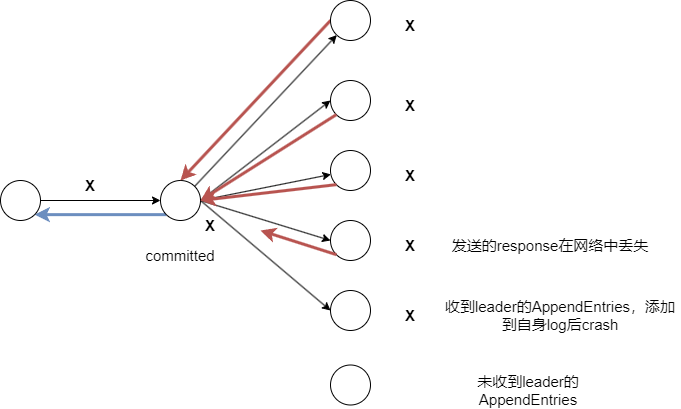
Leader 收到客户端请求后,会生成一个 entry,包含<index,term,cmd>,再将这个 entry 添加到自己的日志末尾后,向所有的节点广播该 entry,要求其他服务器复制这条 entry。
如果 Follower 接受该 entry,则会将 entry 添加到自己的日志后面,同时返回给 Leader 同意。
如果 Leader 收到了多数的成功响应,Leader 会将这个 entry 应用到自己的状态机中,之后可以称这个 entry 是 committed 的,并且向客户端返回执行结果。
raft 保证以下两个性质:
7 主从、集群、分布式的区别
-
分布式:多个系统协同合作完成一个特定任务的系统。分布式是解决中心化管理的问题,把所有的任务叠加到一个节点处理,太慢了。所以把一个大的问题拆分为多个小的问题,并分别解决,最终协同合作。分布式的主要工作是分解任务,将职能拆解。
-
集群:集群主要的使用场景是为了分担请求的压力,也就是在几个服务器上部署相同的应用程序,来分担客户端请求。当压力进一步增大的时候,可能在需要存储的部分,mysql 无法面对很多的写压力。因为在 mysql 做成集群之后,主要的写压力还是在 master 的机器上面,其他 slave 机器无法分担写压力,从而这个时候,也就引出来分布式。
将一套系统拆分成不同子系统部署在不同服务器上(这叫分布式),
然后部署多个相同的子系统在不同的服务器上(这叫集群),部署在不同服务器上的同一个子系统应做负载均衡。
分布式:一个业务拆分为多个子业务,部署在多个服务器上 。
集群:同一个业务,部署在多个服务器上 。
主从、集群和分布式是计算机系统中常见的架构模式,它们有不同的特点和用途:
-
主从(Master-Slave):
- 主从架构是一种单点控制的架构,其中有一个主节点和一个或多个从节点。
- 主节点通常负责处理所有的请求和决策,而从节点用于执行主节点分派的任务或保存数据的备份副本。
- 主从架构通常用于提高系统的可用性和容错性。如果主节点失败,可以将其中一个从节点提升为主节点,以保持系统的运行。
- 主从架构适用于那些需要单一决策权和数据同步的应用,如数据库复制、负载均衡等。
-
集群(Cluster):
- 集群是由多个节点组成的计算机系统,这些节点共同协作以提供某种服务或功能。
- 集群节点通常是对等的,它们可以相互协作,共同处理请求,以提高性能和容错性。
- 集群可以用于各种用途,包括负载均衡、高可用性、并行计算等。
- 集群可以是对称的(每个节点都具有相同的角色和功能)或非对称的(某些节点具有特殊的角色,如主节点)。
-
分布式(Distributed):
- 分布式架构是指系统的组件分布在多个地理位置或计算节点上,它们通过网络通信协同工作。
- 分布式系统的目标是提高性能、扩展性和可用性,允许系统在多个节点上并行执行任务。
- 分布式系统可以包括多个集群,每个集群可能都有自己的主从结构,以满足系统的需求。
- 分布式系统通常需要处理分布式计算、数据同步、一致性和容错性等复杂问题。
总之,主从是一种单点控制的架构,集群是多个节点共同协作的架构,分布式是多个节点分布在不同地方并通过网络通信协同工作的架构。这些不同的架构模式在不同的应用场景中有不同的优点和局限性。选择哪种架构取决于应用的需求和目标。
集群是个物理形态,分布式是个工作方式。分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。
分布式:一个业务分拆多个子业务,部署在不同的服务器上。
集群:同一个业务,部署在多个服务器上