0%
未命名
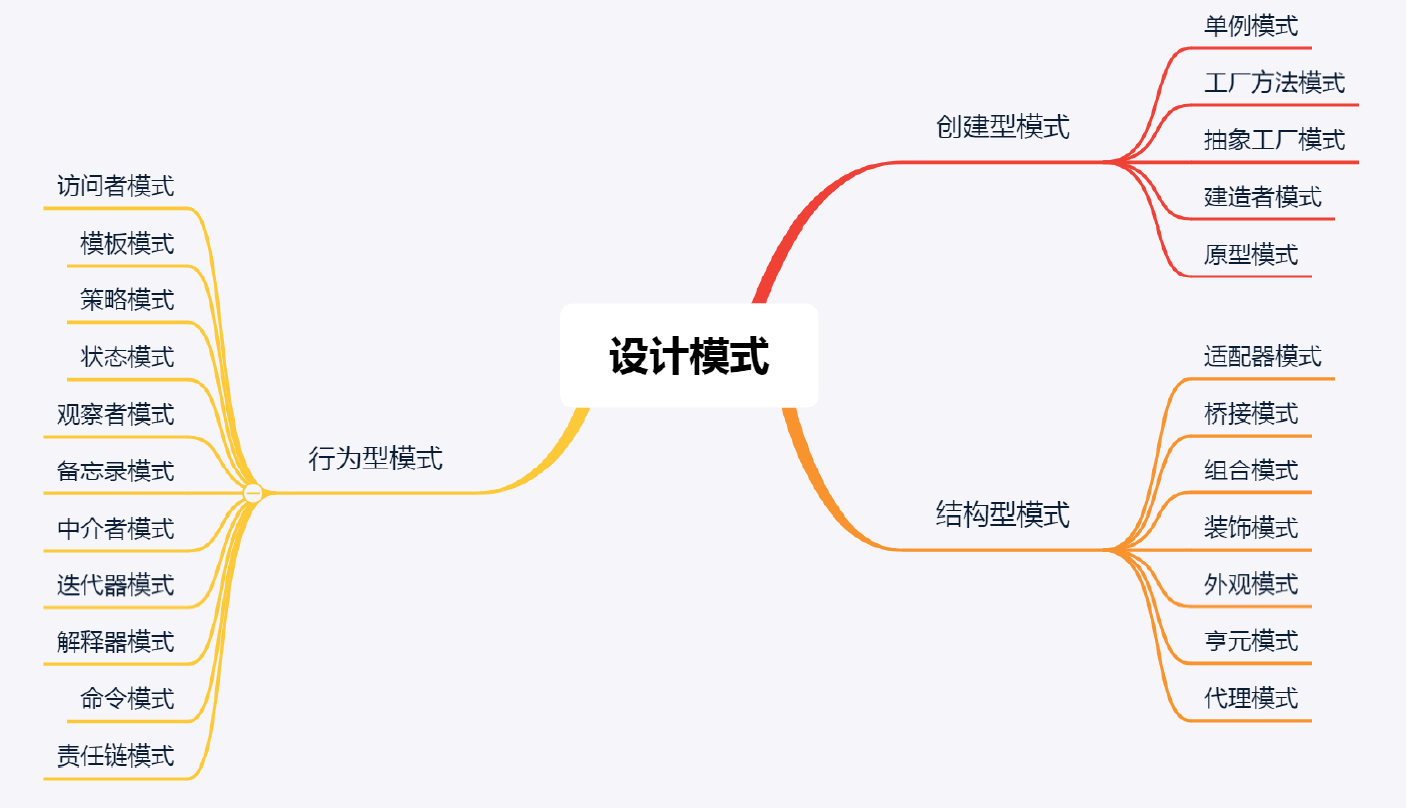
1 创建型模式
1.1 单例模式
单例模式属于创建型模式,⼀个单例类在任何情况下都只存在⼀个实例,构造⽅法必须是私有的、由⾃⼰创建⼀个静态变量存储实例,对外提供⼀个静态公有⽅法获取实例。
1.1.1 常见写法
-
饿汉式
-
懒加载(lazy loading):使用的时候再创建对象
双重校验锁实现对象单例(线程安全):
这⾥的双重检查是指两次⾮空判断,锁指的是 synchronized 加锁,为什么要进⾏双重判断,其实很简单,第⼀重判断,如果实例已经存在,那么就不再需要进⾏同步操作,⽽是直接返回这个实例,如果没有创建,才会进⼊同步块,同步块的⽬的与之前相同,⽬的是为了防⽌有多个线程同时调⽤时,导致⽣成多个实例,有了同步块,每次只能有⼀个线程调⽤访问同步块内容,当第⼀个抢到锁的调⽤获取了实例之后,这个实例就会被创建,之后的所有调⽤都不会进⼊同步块,直接在第⼀重判断就返回了单例。关于内部的第⼆重空判断的作⽤,当多个线程⼀起到达锁位置时,进⾏锁竞争,其中⼀个线程获取锁,如果是第⼀次进⼊则为 null,会进⾏单例对象的创建,完成后释放锁,其他线程获取锁后就会被空判断拦截,直接返回已创建的单例对象。
public class Singleton { |
uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
-
为
uniqueInstance分配内存空间 -
初始化
uniqueInstance -
将
uniqueInstance指向分配的内存地址
1.2 工厂模式
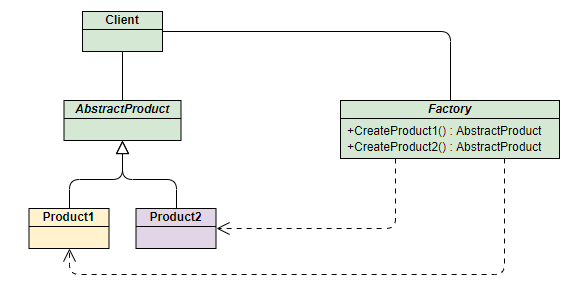
简单⼯⼚模式指由⼀个⼯⼚对象来创建实例,客户端不需要关注创建逻辑,只需提供传⼊⼯⼚的参数。
适⽤于⼯⼚类负责创建对象较少的情况,缺点是如果要增加新产品,就需要修改⼯⼚类的判断逻辑,违背开闭原则,且产品多的话会使⼯⼚类⽐较复杂。
2 行为型模式
2.1 策略模式
多种算法中替换
策略模式属于行为模式的一种,一个类的行为或算法可以在运行时进行更改策略模式(Strategy Pattern)属于对象的⾏为模式。其⽤意是针对⼀组算法,将每⼀个算法封装到具有共同接⼝的独⽴的类中,从⽽使得它们可以相互替换。策略模式使得算法可以在不影响到客户端的情况下发⽣变化。其主要⽬的是通过定义相似的算法,替换 if else 语句写法,并且可以随时相互替换。
1、什么是策略模式?
策略模式是一种行为型设计模式,它允许在运行时更改对象的行为。这种模式通过将算法与使用算法的代码解耦,提供了一种动态选择不同算法的方法。在本文中,我将介绍策略模式的原理、适用场景、技术要点以及以JAVA实现的案例代码。
2、原理介绍策略模式定义了一系列算法或策略,并将每个算法封装在独立的类中,使得它们可以互相替换。通过使用策略模式,可以在运行时根据需要选择不同的算法,而不需要修改客户端代码。在策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 context 对象的执行算法。
未命名
java.lang.IllegalStateException: Failed to load ApplicationContext
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'stateHandlerImpl': Injection of resource dependencies failed; nested exception is org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type 'indiv.lottery.domain.activity.service.stateflow.event.ArraignmentState' available: expected at least 1 bean which qualifies as autowire candidate. Dependency annotations: {@javax.annotation.Resource(shareable=true, lookup=, name=, description=, authenticationType=CONTAINER, type=class java.lang.Object, mappedName=)}
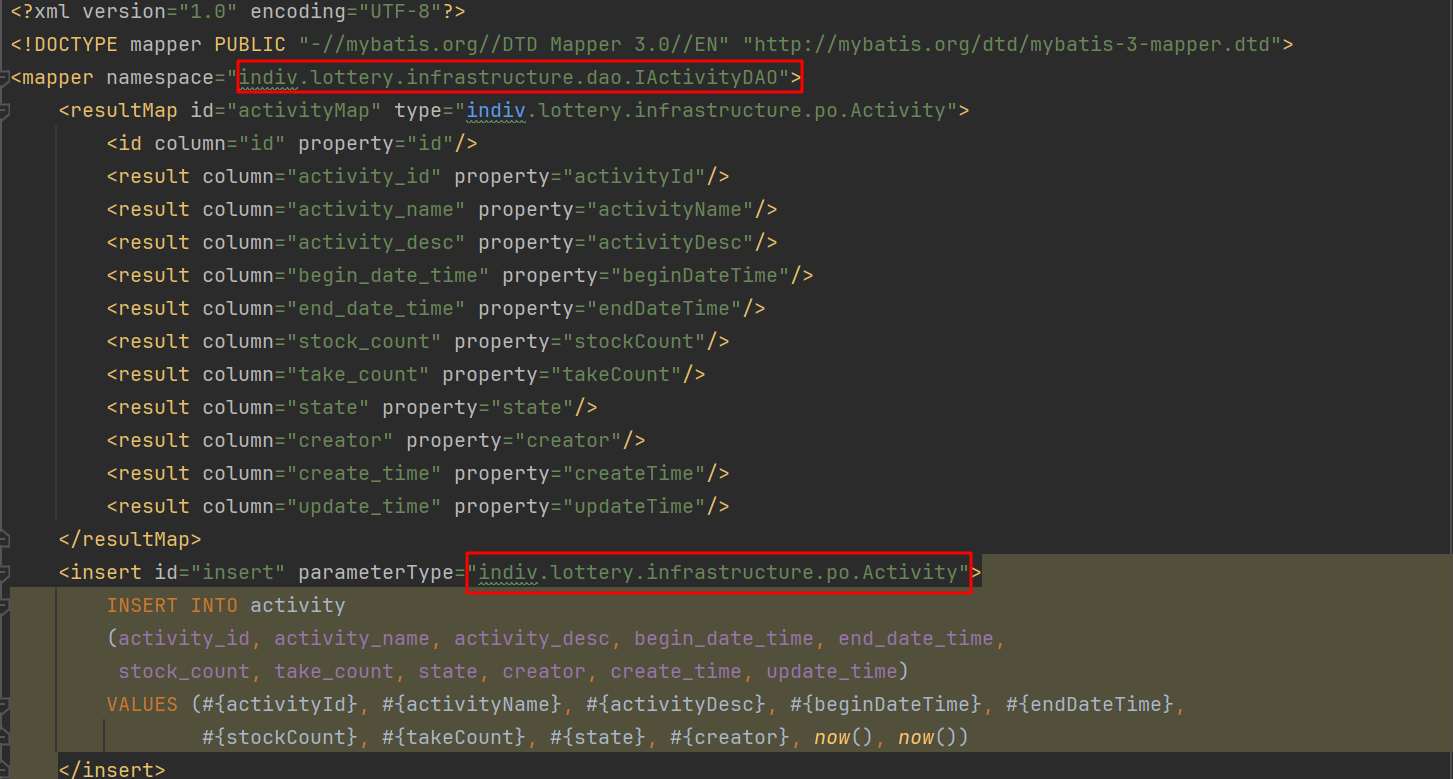
没有定义component组件
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'indiv.lottery.test.domain.ActivityTest': Injection of resource dependencies failed; nested exception is org.springframework.beans.factory.NoSuchBeanDefinitionException:
没有定义service
org.springframework.jdbc.BadSqlGrammarException: |
insert参数名与数据库不匹配
org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): indiv.lottery.infrastructure.dao.IAwardDAO.insertList |
Mysql
Error querying database. Cause: org.springframework.jdbc.CannotGetJdbcConnectionException
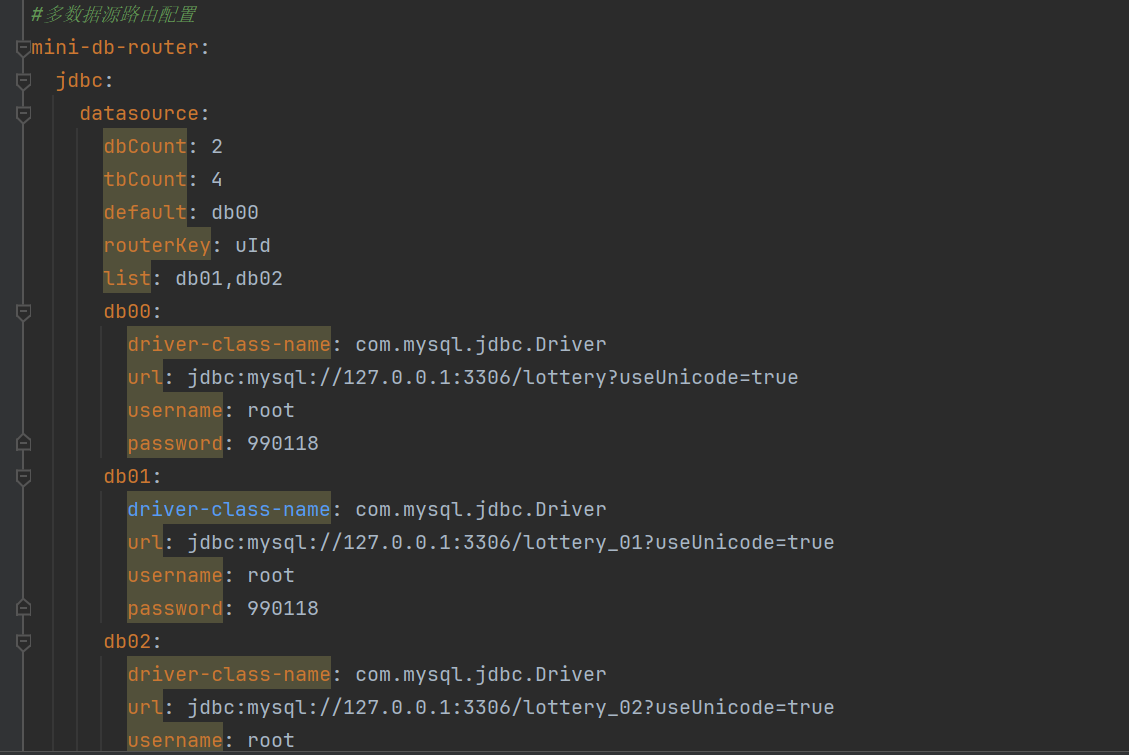
依赖冲突
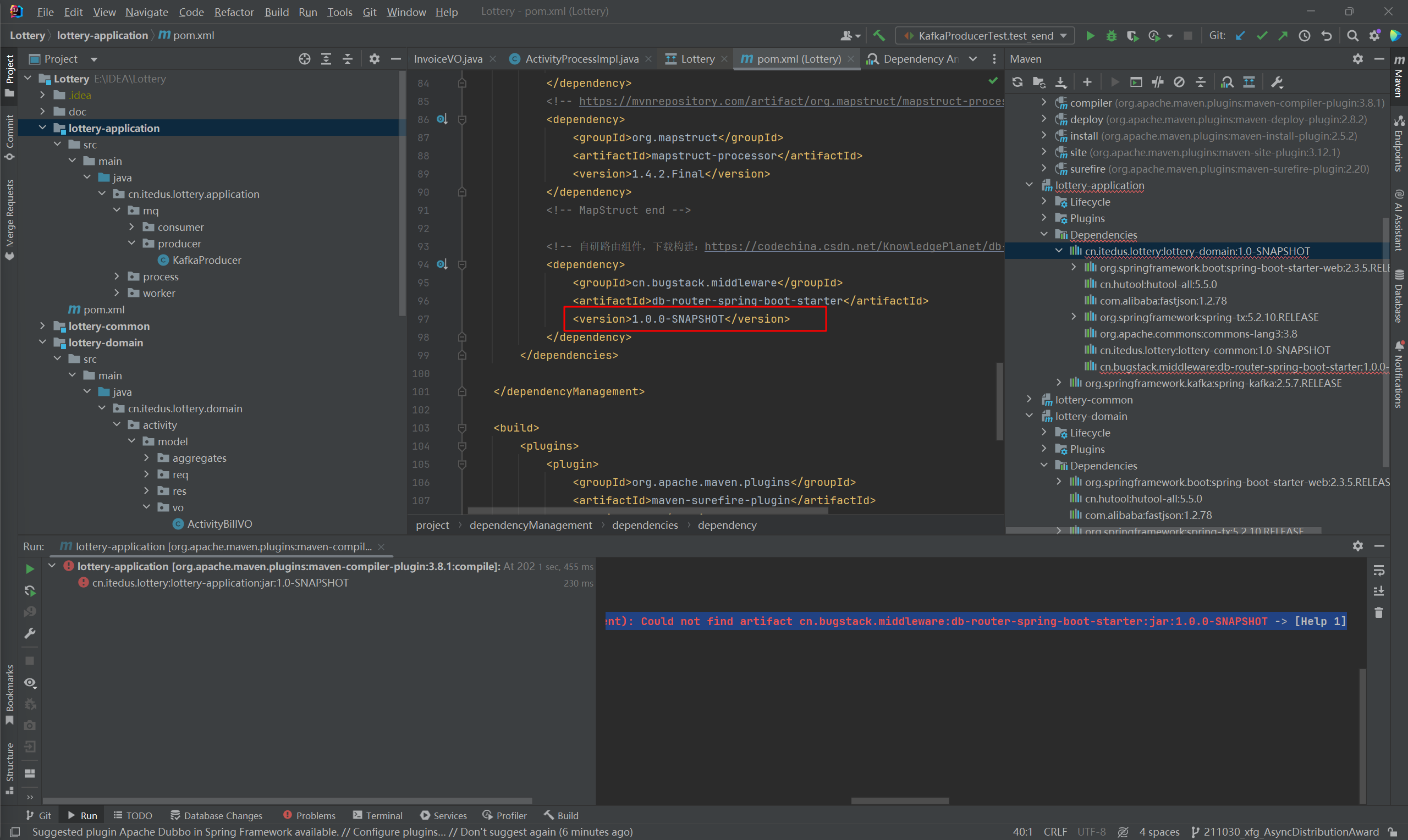
lottery-application: Could not resolve dependencies for project cn.itedus.lottery:lottery-application:jar:1.0-SNAPSHOT: The following artifacts could not be resolved: cn.bugstack.middleware:db-router-spring-boot-starter:jar:1.0.0-SNAPSHOT (absent): Could not find artifact cn.bugstack.middleware:db-router-spring-boot-starter:jar:1.0.0-SNAPSHOT -> [Help 1]
application依赖domain域,但却是在Lottery顶层模块出现版本问题
Java(1):基础(上)
(封装、继承、多态);深拷贝、浅拷贝;接口、抽象类
未命名
1 package
indi :
个体项目,指个人发起,但非自己独自完成的项目,可公开或私有项目,copyright主要属于发起者。
包名为“indi.发起者名.项目名.模块名.……”。
pers :
个人项目,指个人发起,独自完成,可分享的项目,copyright主要属于个人。
包名为“pers.个人名.项目名.模块名.……”。
priv :
私有项目,指个人发起,独自完成,非公开的私人使用的项目,copyright属于个人。
包名为“priv.个人名.项目名.模块名.……”。
team :
团队项目,指由团队发起,并由该团队开发的项目,copyright属于该团队所有。
包名为“team.团队名.项目名.模块名.……”。
com :
公司项目,copyright由项目发起的公司所有。
包名为“com.公司名.项目名.模块名.……”。
2 命名规范
10分钟搞定令人头疼的代码命名规范 | JavaGuide - 知乎 (zhihu.com)
3 Java对象概念:PO BO VO DTO DAO
PO 是 Persistant Object 的缩写,用于表示数据库中的一条记录映射成的 java 对象。PO 仅仅用于表示数据,没有任何数据操作。通常遵守 Java Bean 的规范,拥有 getter/setter 方法。
DAO 是 Data Access Object 的缩写,用于表示一个数据访问对象。使用 DAO 访问数据库,包括插入、更新、删除、查询等操作,与 PO 一起使用。DAO 一般在持久层,完全封装数据库操作,对外暴露的方法使得上层应用不需要关注数据库相关的任何信息。(Maper映射,封装数据库操作的一个映射对象)
VO 是 Value Object 的缩写,用于表示一个与前端进行交互的 java 对象。有的朋友也许有疑问,这里可不可以使用 PO 传递数据?实际上,这里的 VO 只包含前端需要展示的数据即可,对于前端不需要的数据,比如数据创建和修改的时间等字段,出于减少传输数据量大小和保护数据库结构不外泄的目的,不应该在 VO 中体现出来。通常遵守 Java Bean 的规范,拥有 getter/setter 方法。
DTO 是 Data Transfer Object 的缩写,用于表示一个数据传输对象。DTO 通常用于不同服务或服务不同分层之间的数据传输。DTO 与 VO 概念相似,并且通常情况下字段也基本一致。但 DTO 与 VO 又有一些不同,这个不同主要是设计理念上的,比如 API 服务需要使用的 DTO 就可能与 VO 存在差异。通常遵守 Java Bean 的规范,拥有 getter/setter 方法。
BO 是 Business Object 的缩写,用于表示一个业务对象。BO 包括了业务逻辑,常常封装了对 DAO、RPC 等的调用,可以进行 PO 与 VO/DTO 之间的转换。BO 通常位于业务层,要区别于直接对外提供服务的服务层:BO 提供了基本业务单元的基本业务操作,在设计上属于被服务层业务流程调用的对象,一个业务流程可能需要调用多个 BO 来完成。
POJO 是 Plain Ordinary Java Object 的缩写,表示一个简单 java 对象。上面说的 PO、VO、DTO 都是典型的 POJO。而 DAO、BO 一般都不是 POJO,只提供一些调用方法。
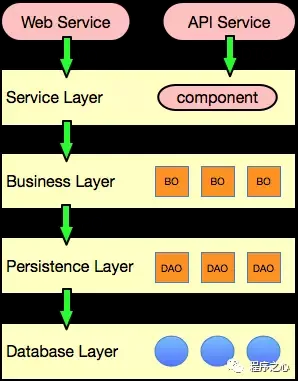
未命名
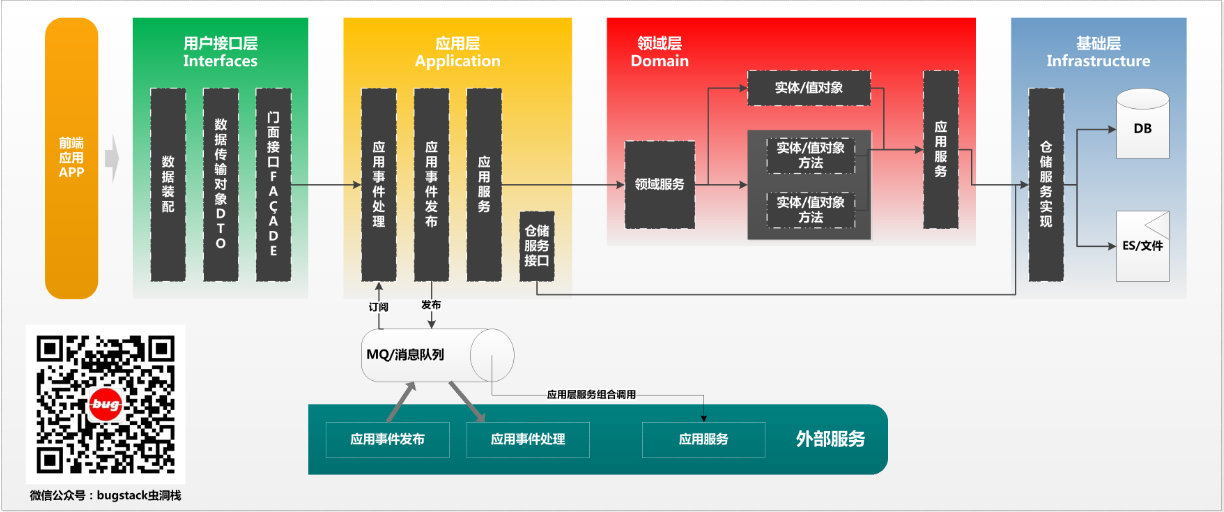
- 应用层{application}
- 应用服务位于应用层。用来表述应用和用户行为,负责服务的组合、编排和转发,负责处理业务用例的执行顺序以及结果的拼装。
- 应用层的服务包括应用服务和领域事件相关服务。
- 应用服务可对微服务内的领域服务以及微服务外的应用服务进行组合和编排,或者对基础层如文件、缓存等数据直接操作形成应用服务,对外提供粗粒度的服务。
- 领域事件服务包括两类:领域事件的发布和订阅。通过事件总线和消息队列实现异步数据传输,实现微服务之间的解耦。
- 领域层{domain}
- 领域服务位于领域层,为完成领域中跨实体或值对象的操作转换而封装的服务,领域服务以与实体和值对象相同的方式参与实施过程。
- 领域服务对同一个实体的一个或多个方法进行组合和封装,或对多个不同实体的操作进行组合或编排,对外暴露成领域服务。领域服务封装了核心的业务逻辑。实体自身的行为在实体类内部实现,向上封装成领域服务暴露。
- 为隐藏领域层的业务逻辑实现,所有领域方法和服务等均须通过领域服务对外暴露。
- 为实现微服务内聚合之间的解耦,原则上禁止跨聚合的领域服务调用和跨聚合的数据相互关联。
- 基础层{infrastructure}
- 基础服务位于基础层。为各层提供资源服务(如数据库、缓存等),实现各层的解耦,降低外部资源变化对业务逻辑的影响。
- 基础服务主要为仓储服务,通过依赖反转的方式为各层提供基础资源服务,领域服务和应用服务调用仓储服务接口,利用仓储实现持久化数据对象或直接访问基础资源。
- 接口层{interfaces}
- 接口服务位于用户接口层,用于处理用户发送的Restful请求和解析用户输入的配置文件等,并将信息传递给应用层。
- 接口服务位于用户接口层,用于处理用户发送的Restful请求和解析用户输入的配置文件等,并将信息传递给应用层。
Mysql安装
mysql安装、mysql.h函数介绍
未命名
异步电路EDA
参与兰州大学异步电路与系统实验室(LZU-ARC)的PinTu项目(面向FPGA ASIC的全异步开源EDA工具链),目前开源到启智平台(OpenI,新一代人工智能开源开放平台)。主要完成对项目源码的部分分析工作,形成介绍文档。对整个项目的整体介绍及部署开源工作。
Gitlet
Gitlet是一个版本控制系统,实现了git的一些特性和功能,相比git在部分功能和实现上进行了简化。支持add、commit、log、checkout、merge等本地仓库操作,同时实现push、fetch、pull等远端仓库命令操作。利用java序列化的方法实现commit和stage对应数据结构的持久化存储,通过sha1算法计算相应的哈希值实现内容可寻址。实现字典树存储commit哈希值,实现根据6位前缀快速查找对应的commit哈希值。
主要包括blob,commit,stage,每一个文件对应一个blob对象,commit和stage分别用于提交和暂存区的对象。
WebServer
实现简易的web服务器,
用户管理、商品管理、订单管理、支付管理、库存管理、物流管理
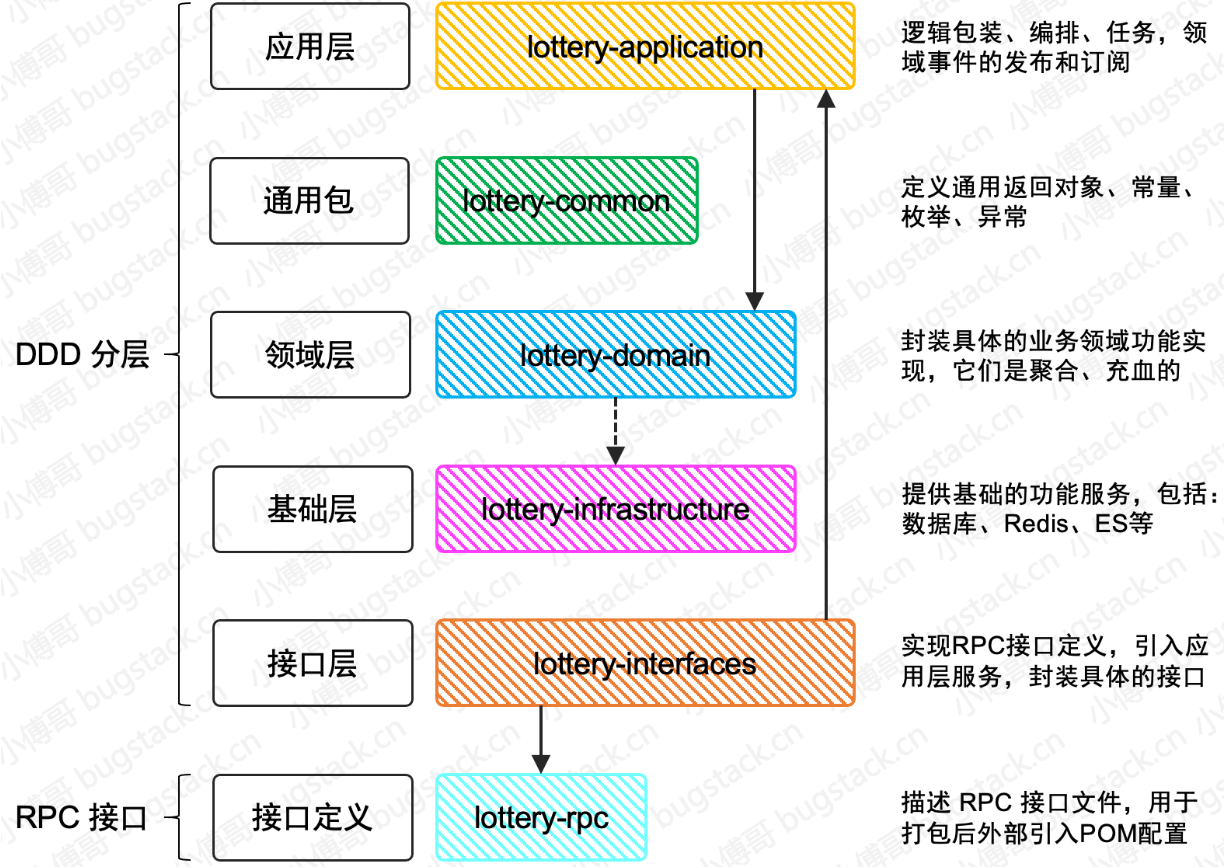
营销活动平台-抽奖系统
Lottery 抽奖系统 项目是一款互联网面向C端人群营销活动类的抽奖系统,可以提供抽奖活动玩法策略的创建、参与、记账、发奖等逻辑功能。在使用的过程中运营人员通过创建概率类奖品的抽奖玩法,对用户进行拉新、促活、留存,通常这样的系统会用在电商、外卖、出行、公众号运营等各类场景中。
抽奖系统以DDD分层结构的方式,搭建整个抽奖系统架构。抽奖系统是营销平台的重要服务之一,用于,满足C端人群拉新、促活、留存的系统,包括规则引擎、抽奖策略、奖品发放等领域服务。通过规则引擎过滤性别、年龄等各类身份来量化出不同人群可参与的抽奖活动。因活动秒杀的并发场景,将秒杀从数据库行级锁优化为Redis分布式锁。解耦抽奖流程,将抽奖流程和发奖流程通过MQ消息串联起来。实现分库分表,将用户数据拆分到不同的库表中去,减轻数据库压力。
-
模块
-
库存秒杀:Redis分布式锁
-
规则引擎:
库表设计:关联关系、字段明细、唯一索引、分库分表、数据同步
未命名
strpbrk
检索字符串 str1 中第一个匹配字符串 str2 中字符的字符,不包含空结束字符。依次检验字符串 str1 中的字符,当被检验字符在字符串 str2 中也包含时,则停止检验,并返回该字符位置。
char *strpbrk(const char *str1, const char *str2) |
- str1 – 要被检索的 C 字符串。
- str2 – 该字符串包含了要在 str1 中进行匹配的字符列表。
strcasecmp
判断字符串是否相等的函数,忽略大小写。s1和s2中的所有字母字符在比较之前都转换为小写。该strcasecmp()函数对空终止字符串进行操作。函数的字符串参数应包含一个(’\0’)标记字符串结尾的空字符。
int strcasecmp (const char *s1, const char *s2); |
strspn
检索字符串 str1 中第一个不在字符串 str2 中出现的字符下标
size_t strspn(const char *str1, const char *str2) |
-
str1 – 要被检索的 C 字符串。
-
str2 – 该字符串包含了要在 str1 中进行匹配的字符列表。
-
返回 str1 中第一个不在字符串 str2 中出现的字符下标。
|
strchr
在参数 str 所指向的字符串中搜索第一次出现字符 c(一个无符号字符)的位置。
char *strchr(const char *str, int c) |
-
str – 要查找的字符串。
-
c – 要查找的字符。
-
如果在字符串 str 中找到字符 c,则函数返回指向该字符的指针,如果未找到该字符则返回 NULL。
strrchr
在参数 str 所指向的字符串中搜索最后一次出现字符 c(一个无符号字符)的位置。
char *strrchr(const char *str, int c) |
-
str – C 字符串。
-
c – 要搜索的字符,通常以整数形式传递(ASCII 值),但是最终会转换回 char 形式。
-
strrchr() 函数从字符串的末尾开始向前搜索,直到找到指定的字符或搜索完整个字符串。如果找到字符,它将返回一个指向该字符的指针,否则返回 NULL。
strcpy
把 src 所指向的字符串复制到 dest。需要注意的是如果目标数组 dest 不够大,而源字符串的长度又太长,可能会造成缓冲溢出的情况。
char *strcpy(char *dest, const char *src) |
strncpy
把 src 所指向的字符串复制到 dest,最多复制 n 个字符。当 src 的长度小于 n 时,dest 的剩余部分将用空字节填充。
char *strcpy(char *dest, const char *src) |
-
dest – 指向用于存储复制内容的目标数组。
-
src – 要复制的字符串。
-
n – 要从源中复制的字符数。
-
该函数返回最终复制的字符串。
stdio.h
flush
刷新流 stream 的输出缓冲区,将缓冲区中的内容写到stream所指的文件中区
|
-
stream – 这是指向 FILE 对象的指针,该 FILE 对象指定了一个缓冲流
-
如果成功,该函数返回零值。如果发生错误,则返回 EOF,且设置错误标识符(即 feof)。
snprintf
用于格式化输出字符串,并将结果写入到指定的缓冲区,与 sprintf() 不同的是,snprintf() 会限制输出的字符数,避免缓冲区溢出。将可变参数**(…)**按照 format 格式化成字符串,并将字符串复制到 str 中,size 为要写入的字符的最大数目,超过 size 会被截断,最多写入 size-1 个字符,并在字符串的末尾添加一个空字符(\0)以表示字符串的结束。
int snprintf ( char * str, size_t size, const char * format, ... ); |
-
str – 目标字符串,用于存储格式化后的字符串的字符数组的指针。
-
size – 字符数组的大小。
-
format – 格式化字符串。
-
… – 可变参数,可变数量的参数根据 format 中的格式化指令进行格式化。
-
snprintf() 函数的返回值是输出到 str 缓冲区中的字符数,不包括字符串结尾的空字符 \0。
stat
获取文件状态
C语言stat()函数:获取文件状态 - 极客先锋 - 博客园 (cnblogs.com)
|
函数参数处理
va_start
初始化 ap 变量,它与 va_arg 和 va_end 宏是一起使用的。last_arg 是最后一个传递给函数的已知的固定参数,即省略号之前的参数。
|
-
ap – 这是一个 va_list 类型的对象,它用来存储通过 va_arg 获取额外参数时所必需的信息。
-
last_arg – 最后一个传递给函数的已知的固定参数。
//sum(3,10,20,30) |
vsnprintf
sprintf、snprintf、vsprintf、vsnprintf格式化函数分析_c++ sprintf vsprintf详解-CSDN博客
使用参数列表发送格式化输出到字符串
int vsnprintf(char *str, size_t size, const char *format, va_list ap); |
-
str – 目标字符串。
-
size – 最大格式化的字符长度。
-
format – 格式化模式
-
arg – 可变参数列表对象,应由<stdarg>中定义的va_start 宏初始化。