0%
未命名
哈希表
哈希表、哈希集合
未命名
1 简洁写法
class UnionFind{ |
2 路径压缩+按秩合并
1319. 连通网络的操作次数 - 力扣(LeetCode)(模板,更清晰)
class UnionFind { |
3 删除边
并查集优化——树上删除操作 - 知乎 (zhihu.com)
并查集-并查集的删除操作 - 僚机 - 博客园 (cnblogs.com)
并查集——简单易懂(内附并查集删除操作)_可删并查集-CSDN博客
未命名
linux
bug
-
Linux执行.sh文件,提示No such file or directory的问题的解决方法
fileformat格式错误
vim打开sh文件
:set ff(fileformat=dos)
:set ff=unix
:wq -
Command ‘clang’ not found, but can be installed with
[Fixing ‘clang’ and ‘clang++’ not found after installing ‘clang-3.5’ package | DeviceTests](https://devicetests.com/fixing-clang-and-clang-not-found#:~:text=Open a terminal and run the following command%3A,the repository%2C and installs it on your system.)
Cmake
设置cmake编译器
未命名
0.1 左值和右值
- lvalue(ell-value):
- 左值是可寻址的变量,有持久性。既可以出现在等号左边,也可以出现在等号右边
- 左值表达式的求值结果是一个对象或者一个函数,有些左值不能成为赋值语句的左侧运算对象(const)。当对象被用作左值的时候,用的是object’s identity(its location in memory)。
- rvalue(are-value):当一个对象被用作右值的时候,用的是对象的值(the object’s content)
- 右值一般是不可寻址的常量,或在表达式求值过程中创建的无名临时对象,短暂性的
int a; // a 为左值 |
需要右值时,可以使用左值,反之不行
-
左值引用:引用一个对象;
-
右值引用(rvalue reference):就是必须绑定到右值的引用,C++11中右值引用可以实现“移动语义”,通过 && 获得右值引用。必须绑定到右值的引用,可以绑定到一个将要销毁的对象
int x = 6; // x是左值,6是右值 |
1 chapt 12
smart pointer:管理动态对象
shared_ptr:允许多个指针指向同一个对象
unique_ptr:独占所指向的对象
weak_ptr:弱引用,指向shared_ptr所管理的对象
管理动态内存:
-
忘记delete动态分配的内存(内存泄漏)
-
在对象delete后使用
-
同一块内存delete多次
1.1 smart pointer



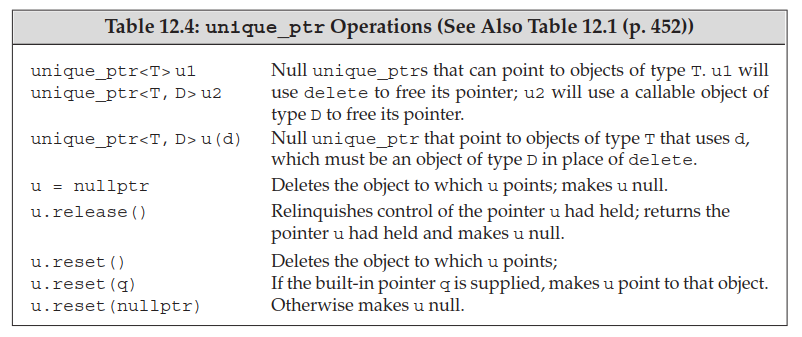
1.2 unique_ptr
未命名
1 STL
- Sequence Containers:顺序容器
- vector:动态数组,O(1)的随机存取。在尾部增删的复杂度是O(1),可以用作stack。
- list:双向链表,不支持随机存取。
- deque:双端队列,支持O(1)的随机存取,O(1)时间的头部增删和尾部增删。
- array:固定大小的数组
- forward_list:单向链表
- Container Adaptors:基于其它容器实现的数据结构
- stack:后入先出(LIFO),默认基于deque实现。stack常用于深度优先搜索,字符串匹配以及单调栈问题
- queue:先入先出(FIFO),默认基于deque实现,常用于广度优先搜索。
- priority_queue:最大值先出(默认)的数据结构,默认基于vector实现堆结构,可以在O(nlogn)时间排序数组,O(logn)插入值,O(1)时间获取最大值,O(logn)删除最大值。
- Associative Containers:实现了排好序的数据结构
- set:有序集合,元素不可重复,底层默认为红黑树,即一种特殊的二叉查找树(BST)。在O(nlogn)时间排序数组,O(logn)时间插入、删除、查找任意值,O(logn)时间获得最大值或最小值。priority_queue不支持删除任意值。
- multiset:支持重复元素的set
- map:有序映射或有序表,在set的基础上加上映射关系,可以对每个元素key存一个value
- multimap:支持重复元素的map
- Unordered Associative Containers:对每个Associative Containers实现哈希版本
- unordered_set:哈希集合,可以在O(1)的时间快速插入、查找、删除元素,常用于快速的查询一个元素是否在这个容器内。
- unordered_multiset:支持重复元素的unordered_set
- unordered_map:哈希映射或和哈希表,在unordered_set的基础上加上映射关系,可以对每一个元素key存一个值value。在某些情况下,如果key的范围已知且较小,可以用vector代替unordered_map,用位置表示key,且每个位置的值表示value
- unordered_multimap:支持重复元素的unordered_map
2 set、multiset
C++ STL multiset容器详解 (biancheng.net)
multiset可以存储int, string, struct, class等类型,对于自定义类型需要实现比较函数
struct Node{ |
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个(注意,是已排好序的第一个)元素的双向迭代器。 |
| end() | 返回指向容器最后一个元素(注意,是已排好序的最后一个)所在位置后一个位置的双向迭代器 |
| rbegin() | 返回指向最后一个(注意,是已排好序的最后一个)元素的反向双向迭代器。 |
| rend() | 返回指向第一个(注意,是已排好序的第一个)元素所在位置前一个位置的反向双向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改容器内存储的元素值。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改容器内存储的元素值。 |
| crbegin() | 和 rbegin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改容器内存储的元素值。 |
| crend() | 和 rend() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改容器内存储的元素值。 |
| find(val) | 查找值为 val 的第一个元素,如果成功找到,则返回指向该元素的迭代器;反之,则返回end() 方法一样的迭代器。 |
| lower_bound(val) | 返回第一个大于或等于 val 的元素的迭代器,即元素位置。 |
| upper_bound(val) | 返回第一个大于 val 的元素的迭代器。 |
| equal_range(val) | 该方法返回一个 pair ,(pair.first,pair.second)=(lower_bound(),upper_bound()),表示值为val的范围。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前 multiset 容器中存有元素的个数。 |
| max_size() | 返回 multiset 容器所能容纳元素的最大个数 |
| insert(val) | 向 multiset 容器中插入元素。 |
| erase(iter) | 删除迭代器所指位置元素,无返回值 |
| erase(val) | 删除值为val的所有元素,返回删除个数 |
| swap() | 交换 2 个 multiset 容器中存储的所有元素。这意味着,操作的 2 个 multiset 容器的类型必须相同。 |
| clear() | 清空 multiset 容器中所有的元素,即令 multiset 容器的 size() 为 0。 |
| emplace() | 在当前 multiset 容器中的指定位置直接构造新元素。其效果和 insert() 一样,但效率更高。 |
| emplace_hint() | 和emplace()构造新元素的方式是一样的,不同之处在于,使用者必须为该方法提供一个指示新元素生成位置的迭代器,并作为该方法的第一个参数。 |
| count(val) | 查找值为 val 的元素的个数,并返回。 |
c++语言中,multiset是
2.1.1 简单应用:
通过一个程序来看如何使用multiset:
|
对于输入数据:32 61 12 2 12 0,该程序的输出是:2 12 12 32 61。
2.1.2 放入自定义类型的数据:
不只是int类型,multiset还可以存储其他的类型诸如 string类型,结构(struct或class)类型。而我们一般在编程当中遇到的问题经常用到自定义的类型,即struct或class。例如下面的例子:
struct rec{int x,y;}; |
不过以上的代码是没有任何用处的,因为multiset并不知道如何去比较一个自定义的类型。怎么办呢?我们可以定义multiset里面rec类型变量之间的小于关系的含义(这里以x为第一关键字为例),具体过程如下:
定义一个比较类cmp,cmp内部的operator函数的作用是比较rec类型a和b的大小(以x为第一关键字,y为第二关键字),告诉了序列h如何去比较里面的元素(重载运算符)
3 set、unordered_set区别
// unordered_set<pair<int, int>> test; # error: use of deleted function function |
4 vector
| 成员方法 | 功能 |
|---|---|
| nums.erase(nums.begin()+index) | 删除下标为index处的元素 |
5 array
| 成员方法 | 功能 |
|---|---|
| array<int, 26> cnt = {}; | 初始化为0,没有{}则为默认初始化 |
6 string
cin:遇到空格结束读取
getline(cin, line):读取一行(包括换行符),line不包括换行符
to_string
stoi
| 成员方法 | 功能 | 头文件 |
|---|---|---|
| s.push_back(ch) | 在后面添加一个字符 | |
| s.append(args) | 参数字符串可以是string,也可以是c_str | |
| s.append(args,cnt) | 从args起始位置添加cnt个字符 | |
| s.substr(pos,n) | 截取字符串,从pos位置开始截取n个字符 | |
| count(s.begin(), s.end(), ‘A’) | 字符计数 | algorithm |
| reverse(s.begin(),s.end()) | 字符串翻转 | algorithm |
| num.find_last_not_of(‘0’) | 从后往前第一个不为0的下标 |
6.1 字符相关函数
#include <ctype.h>
| cctype | |
|---|---|
 |
| 成员方法 | 描述 |
|---|---|
| isalnum() | 是否为数字或者字符 |
| tolower( ) | 将字符变为小写字符 |
6.2 根据空格分割字符串
string line="this student is studious"; |
7 priority_queue
priority_queue<int> pq; |
| 成员方法 | 功能 |
|---|---|
| pq.push(val) | 插入一个元素 |
| pq.pop() | 弹出最值 |
| pq.top() | 返回最值 |
8 algorithm
8.1 sort
|
(6条消息) 浅析C/C++中sort函数的用法_WHEgqing的专栏-CSDN博客
8.2 lower_bound
查找大于或者等于x的第一个位置
未命名
前缀和适用于数组不变适用于单点更新,区间查询
| 方法 | 构造 | 查询 | 修改 | 适用 |
|---|---|---|---|---|
| 前缀和 | O(n) | O(1) | 数组不变 | |
| 树状数组 | O(nlogn) | O(logn) | O(logn) | 区间查询,单点更新 |
307. 区域和检索 - 数组可修改 - 力扣(LeetCode)
-
数组不变,求区间和:「前缀和」、「树状数组」、「线段树」
-
多次修改某个数(单点),求区间和:「树状数组」、「线段树」
-
多次修改某个区间,输出最终结果:「差分」
-
多次修改某个区间,求区间和:「线段树」、「树状数组」(看修改区间范围大小)
-
多次将某个区间变成同一个数,求区间和:「线段树」、「树状数组」(看修改区间范围大小)
未命名
priority_queue(heap)
push
template<typename _RandomAccessIterator, typename _Distance, typename _Tp, |
未命名
next_permutation
next_permutation()是按字典序依次排列的,当排列到最大的值是就会返回false.
生成给定序列的下一个排列,按字典序生成下一个排列。如果有下一个排列,返回true,否则返回false
template <typename _BidirectionalIterator, typename _Compare> |
参考
使用next_permutation()的坑,你中招了么?_辉小歌的博客-CSDN博客
C++神奇的next_permutation - 知乎 (zhihu.com)